
mojo's Blog
Parallelism 본문
※ Exploiting parallel execution
지금까지는 스레드를 사용하여 I/O 지연을 처리했다.
- 예를 들어, 클라이언트당 하나의 스레드를 사용하여 다른 스레드를 지연시키는 것을 방지한다.
Multi-core/Hyperthreaded CPU는 또 다른 기능을 제공한다.
- 병렬로 실행되는 스레드에 작업 분산
- 독립적인 작업이 많은 경우 자동으로 발생
- 예를 들어, 많은 응용 프로그램을 실행하거나 많은 고객에게 서비스를 제공한다.
- 또한 코드를 작성하여 하나의 큰 작업을 더 빨리 진행할 수 있다.
- 다중 병렬 하위 그룹으로 구성함으로써
Hyperthreading 이란?
하이퍼스레딩은 Intel 이 동시 멀티스레딩을 구현한 기술이다.
물리상 실행 장치 한 개에 가상 실행 장치(virtual 또는 logical core) 두 개를 할당해 성능을 높이려는 기술이다.
운영 체제는 코어 한 개당 스레드가 두 개씩 추가되어 싱글 코어(1개)는 듀얼 코어(2개), 듀얼 코어(2개)는 쿼드코어(4개), 트리플 코어(3개)는 헥사(6개)코어, 쿼드코어(4개)는 옥타코어(8개), 헥사(6개)코어는 도데카(12개)코어, 옥타코어(8개)는 헥사 데시멀 코어(16개)가 장착 되어있다고 인식한다.

HTT를 표면상에 기술한 그림이다.
RAM에서 instruction을 fetch 하고 (다른 색으로 칠된 상자들은 다른 프로그램 네 개의 명령을 의미), front end에 의해 decoding 후 재정렬한 다음, 동일한 클럭 사이클 동안 다른 프로그램 두 개에서 명령을 실행할 수 있는 실행 코어로 전달된다.
※ Typical Multicore Processor

메모리에 대한 일관된 뷰로 작동하는 다중 프로세서이다.
Core 내부에 있는 L1, L2 는 private cache 로 L1 의 d-cache 는 data 를, i-cache 는 instruction 을 담당하고 L2 unified cache 는 data 와 instruction 을 담당하고 있다.
그리고 Main memory 와 다이렉트로 연결된 L3 는 public cache 로 모든 core 들과의 공유가 이루어진 형태이다.

위와 같은 구조로 Core register 부터 main memory 까지 피라미드 구조처럼 형성이 된 것을 볼 수 있다.
상단으로 갈 수록 빠르고 비용이 비싸며 하단으로 갈 수록 느리고 비용이 저렴한 특징이 있다.
※ Example 1 : Parallel Summation
합계 번호 0, …, n-1
- ((n-1)*n)/2 까지 더해야 한다.
파티션 값 1, …, n-1 을 t 범위로 분할
- 각 범위의 ⌊ n/t ⌋ 값
- 각 t 개의 스레드는 1개의 범위를 처리한다.
- 단순성을 위해, n은 t의 배수라고 가정한다.
여러 스레드가 할당된 범위에서 병렬로 작동할 수 있는 다양한 방법을 고려해 본다.
※ First attempt : psum-mutex
가장 간단한 접근 방식: 스레드 합계는 세마포어 뮤텍스로 보호되는 전역 변수에 해당한다.
void *sum_mutex(void *vargp); /* Thread routine */
/* Global shared variables */
long gsum = 0; /* Global sum */
long nelems_per_thread; /* Number of elements to sum */
sem_t mutex; /* Mutex to protect global sum */
int main(int argc, char **argv)
{
long i, nelems, log_nelems, nthreads, myid[MAXTHREADS];
pthread_t tid[MAXTHREADS];
/* Get input arguments */
nthreads = atoi(argv[1]);
log_nelems = atoi(argv[2]);
nelems = (1L << log_nelems);
nelems_per_thread = nelems / nthreads;
sem_init(&mutex, 0, 1);
/* Create peer threads and wait for them to finish */
for (i = 0; i < nthreads; i++) {
myid[i] = i;
Pthread_create(&tid[i], NULL, sum_mutex, &myid[i]);
}
for (i = 0; i < nthreads; i++)
Pthread_join(tid[i], NULL);
/* Check final answer */
if (gsum != (nelems * (nelems-1))/2)
printf("Error: result=%ld\n", gsum);
exit(0);
}
/* Thread routine for psum-mutex.c */
void *sum_mutex(void *vargp)
{
long myid = *((long *)vargp); /* Extract thread ID */
long start = myid * nelems_per_thread; /* Start element index */
long end = start + nelems_per_thread; /* End element index */
long i;
for (i = start; i < end; i++) {
P(&mutex);
gsum += i;
V(&mutex);
}
return NULL;
}
sum_mutex 함수를 살펴보도록 하자.
모든 스레드들이 공유할 수 있는 gsum 변수에 [start, end) 에 해당하는 값을 더해준다.
최종적으로 gsum 은 (n*(n-1))/2 값이 나와야 하며 나오지 않을 경우는 에러이다.
※ psum-mutex Performance
Shark machine with 8 cores, n=2^31

Nasty surprise :
- 단일 스레드가 굉장히 느리다.
- 코어를 더 많이 사용할수록 느려짐
Lock 을 잡고 푸는 과정에서 스레드끼리 contention 이 발생하게 되므로 이상적인 결과가 아니다.
※ Next Attempt : psum-array
피어 스레드는 전역 배열의 원소 psum[i] 에 합산된다.
Main 은 스레드가 끝나기를 기다렸다가 모든 psum의 원소를 합한다.
이 과정에서 뮤텍스 동기화가 필요 없는 것이 핵심이다.
/* Thread routine for psum-array.c */
void *sum_array(void *vargp)
{
long myid = *((long *)vargp); /* Extract thread ID */
long start = myid * nelems_per_thread; /* Start element index */
long end = start + nelems_per_thread; /* End element index */
long i;
for (i = start; i < end; i++) {
psum[myid] += i;
}
return NULL;
}
스레드의 갯수가 psum 배열 사이즈보다 작은 경우에 위와 같은 코드로 Lock 을 하지 않고 실행할 수 있다.
그 이유는 각 스레드들은 독립적인 psum 배열의 원소를 사용하기 때문이다.
※ psum-array Performance

이전과는 다르게 performance 가 향상된 것을 볼 수 있다.
※ Next Attempt : psum-local
피어 스레드를 로컬 변수(레지스터)로 합쳐서 메모리 참조를 감소한다.
/* Thread routine for psum-local.c */
void *sum_local(void *vargp)
{
long myid = *((long *)vargp); /* Extract thread ID */
long start = myid * nelems_per_thread; /* Start element index */
long end = start + nelems_per_thread; /* End element index */
long i, sum = 0;
for (i = start; i < end; i++) {
sum += i;
}
psum[myid] = sum;
return NULL;
}
각 스레드마다 전역변수로 선언된 배열 psum 의 원소를 합하는 방식이 아닌 각 스레드 마다 지역변수로 선언한 sum 을 가지고 합한 다음에 psum 의 원소에다 할당하는 방식이다.
이 방식은 전역 변수를 참조하지 않고 각 스레드에 존재하는 지역 변수를 참조하는 방식이다.
아까 봤던 피라미드 구조를 생각해보자.
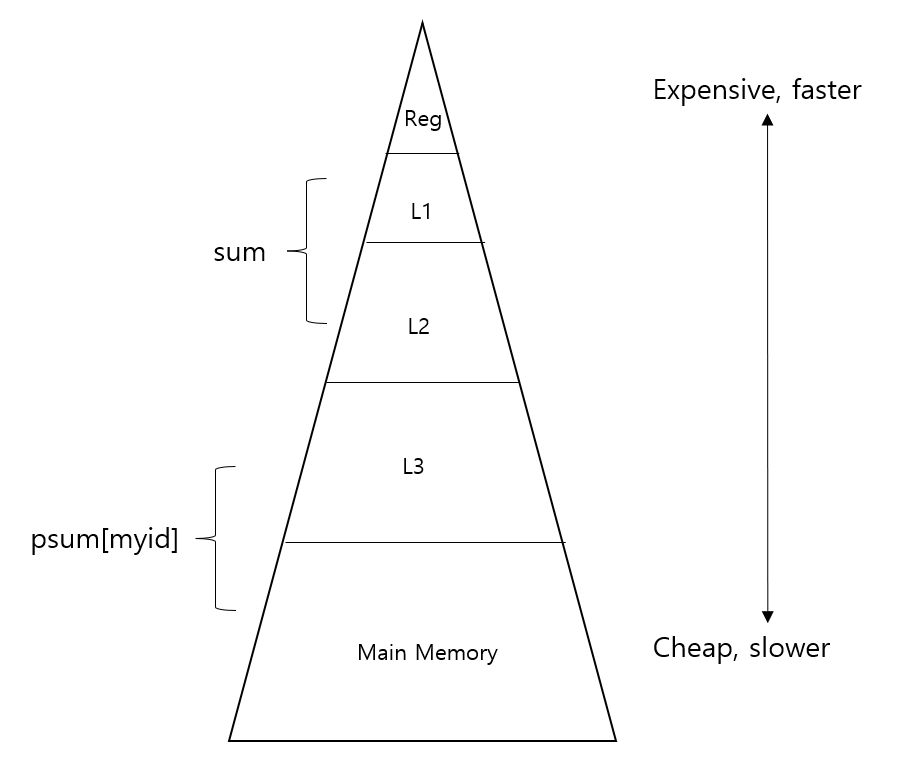
대략적으로 sum 은 private cache 에서, psum 은 public cache 또는 main memory 에서 값을 참조하여 가져온다고 생각해보자.
그렇다면 로컬 변수인 sum 은 전역 변수인 psum 보다 더 빠르게 값을 가져올 수 있게 된다.
psum-local 의 performance 를 살펴보도록 하자.

psum-array 보다 더 빠르게 실행되는 것으로 로컬 변수로 인해 최적화된 것을 알 수 있다.
※ Characterizing Parallel Program Performance
p 는 프로세서 코어의 갯수이며 \(T_{k}\)는 k 개의 core를 사용하는 실행 시간이다.
Def. Speedup: \(S_{p} = T_{1} / T_{p}\)
\(T_{1}\) 이 1 코어에서 실행되는 코드의 병렬 버전 실행 시간인 경우 \(S_{p}\) 는 relative speedup 이다.
\(T_{1}\) 이 1 코어에서 실행되는 순차적 버전의 코드 실행 시간인 경우 \(S_{p}\) 는 absolute speedup 이다.
absolute speedup 은 병렬화의 이점에 대한 훨씬 더 리얼한 측정값이다.
Def. 효율: \(E_{p} = S_{p} /p = T_{1} / (pT_{p})\)
- 범위 (0, 100] 의 백분율로 보고된다.
- 병렬화로 인한 오버헤드 측정
※ Performance of psum-local
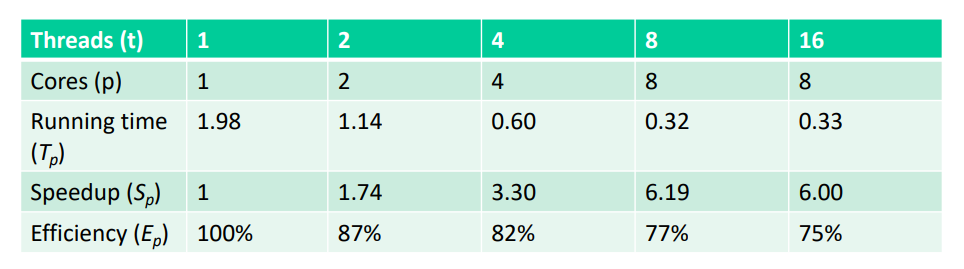
효율성은 양호하지만 그렇게 좋지는 않다.
이 예제는 쉽게 병렬화할 수 있으며 실제 코드는 종종 병렬화하기가 훨씬 어렵다.
스레드의 갯수가 8 에서 16 으로 넘어가는 지점의 \(T_{p}, S_{p}, E_{p}\) 를 살펴보도록 하자.
우선 스레드의 갯수가 16 일 경우 Core 갯수는 동일하게 8 으로 하이퍼스레딩 임을 알 수 있다.
그렇다면 코어 하나에 두 개의 스레드가 할당되는 방식으로 이로 인해 두 스레드 간의 contention 이 발생하게 되므로 그로 인한 overhead 로 인해 \(T_{p}\) 는 증가되고 \(S_{p}, E_{p}\) 는 감소된 것을 확인할 수 있다.
여기서 핵심은 스레드 갯수가 8개를 넘어선다고 해서 바로 \(S_{p}, E_{p}\) 가 감소되는 것이 아니다.
(8, 16] 범위 내에서 특정 스레드의 갯수를 지점으로 하여 \(S_{p}, E_{p}\) 가 증가되다가 감소될 수 있다.
추가로 \(E_{p}\) 가 100% 가 아니라면 그에 대응하는 Loss \(1 - E_{p}\) 도 존재한다.
Loss 는 overhead 로 값이 높을수록 overhead 가 크게 되므로 효율성이 떨어지는 것을 알 수 있다.
※ Memory Consistency
출력 가능한 값은 무엇일까?
- 메모리 일관성 모델에 따라 다름
- 하드웨어가 동시 액세스를 처리하는 방법에 대한 추상적 모델
순차적 일관성
- 각 개별 스레드와 일관된 전체 효과
- 그렇지 않으면 임의로 인터리빙
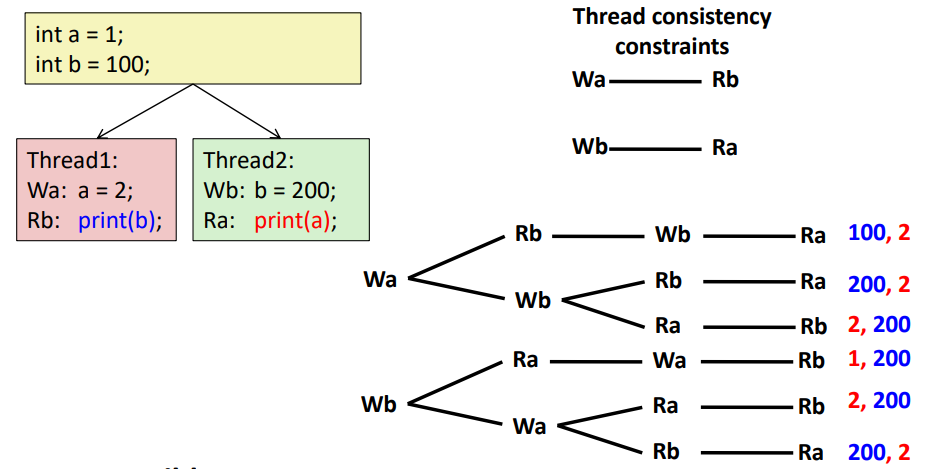
위와 같이 스레드 사이에 인터리빙이 되면서 만들어질 수 있는 output 은 위와 같다.
우선 a, b 는 스레드 끼리 공유 가능한 전역 변수이다.
이때, 불가능한 결과는 100, 1 그리고 1, 100 이다.
그 이유는 print 하기 전에 Wa, Wb 가 적어도 하나는 실행이 되어야 하는데 그렇지 못한 경우이기 때문이다.
※ Non-Coherent Cache Scenario
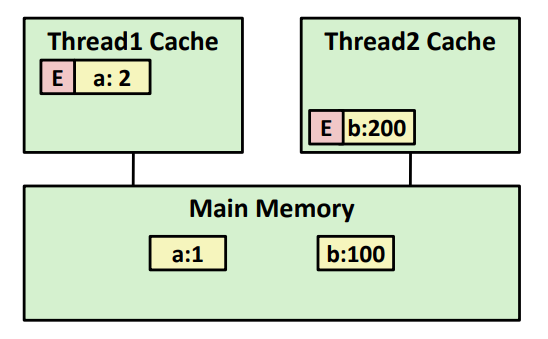
캐시 간 조정 없이 캐시 write 를 진행한다고 해보자.
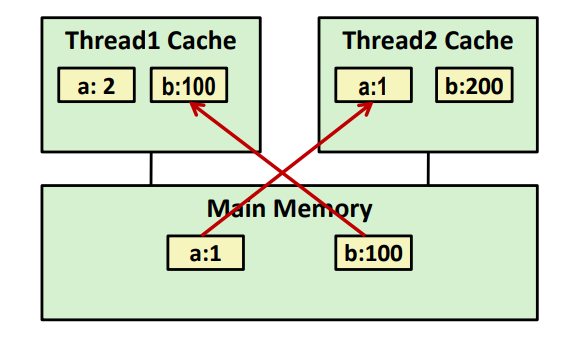

스레드 1, 2 캐시에 각각 a = 1, b = 100 이 존재하는 상황이다.
이때, 스레드 1의 캐시는 a = 2 로 업데이트 하고 스레드 2의 캐시는 b = 200 으로 업데이트 한 상황이다.
그러나 스레드 1에서 b를 출력하면 100, 스레드 2에서 a를 출력하면 1이 출력되게 된다.
이는 각 스레드 마다 대응하는 캐시에 값을 가져오기 때문에 memory consistency 를 깨뜨리는 상황이 된 것이다.
캐시 간에 조정이 없어서 생긴 문제로 이를 해결하기 위한 방법은 Snoopy Caches 가 존재한다.
※ Snoopy Caches
Tag each cache block with state
- Invalid : 값을 사용하지 않음
- Shared : copy 본을 읽을 수 있음
- Exclusive : copy 본을 작성할 수 있음
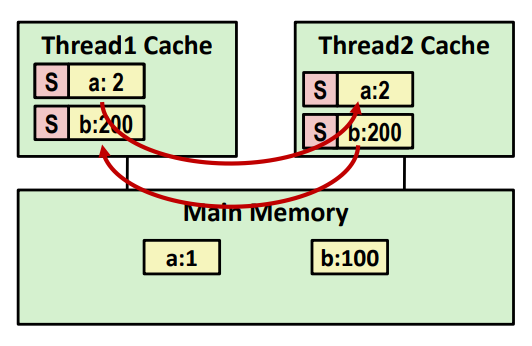
스레드 1 에서 a = 2 를 실행하여 E-tag 가 붙으며 a : 2 가 되고 스레드 2 에서 b = 200 을 실행하여 E-tag 가 붙으며 b : 200 이 되었다.
그 후에 print 를 하려고 하면 Snoopy Cache 는 캐시가 E-tag 블록 중 하나에 대한 요청을 확인하며 자연스럽게 캐시에서 값을 공급하며 해당 tag 를 S 로 설정하게 된다.
이러한 매커니즘은 software 가 아닌 hardware 로 구현이 되어 있다고 한다.
'학교에서 들은거 정리 > 시스템프로그래밍' 카테고리의 다른 글
| Malloc (0) | 2022.05.27 |
|---|---|
| Dymaic Memory Allocation (0) | 2022.05.22 |
| Synchronization : Advanced (0) | 2022.05.12 |
| Synchronization: Basics (0) | 2022.04.28 |
| Concurrent Programming (0) | 2022.04.14 |



