
mojo's Blog
Concurrent Programming 본문
※ Concurrent Programming is Hard!
동시 프로그램의 고전적인 문제 클래스:
- Races : 결과는 시스템 내에 다른 곳의 arbitrary scheduling 결정에 따라 달라진다.
- 예: 비행기의 마지막 자리는 누가 차지할까?
- Deadlock : 잘못된 자원 할당으로 인해 앞으로 진행되지 않게 된다.
- 예: 교통 체증
- Livelock / Starvation / Fariness : 외부 event, 시스템 scheduling 결정으로 하위 작업 진행이 방해될 수 있다.
- 예: 사람들은 항상 내 앞에 줄서서 뛰어오른다.
※ Iterative Servers
Iterative Servers 는 한 번에 하나의 요청을 처리한다.

만약 Client 1, 2, 3 가 존재하고 Iterative server 가 존재한다고 할 때, 동시에 connect 를 하게 된다면?

위와 같이 동시에 client 3명이 connect 를 할 경우 어떤 client 는 바로 write, read 가 가능하지만 어떤 client 는 다른 client 들이 모두 accept 되고 close 가 끝나야만 실행이 된다.
즉, 동시에 처리를 하지 못해서 수많은 클라이언트의 처리를 할 경우에 어떤 client 는 단번에 처리하지만 다른 clinet 는 1 시간 넘게 기다려도 처리되지 못하는 현상이 일어날 것으로 보인다.
※ Where Does Second Client Block?
두 번째 client 는 iterative server 에 연결을 시도한다.
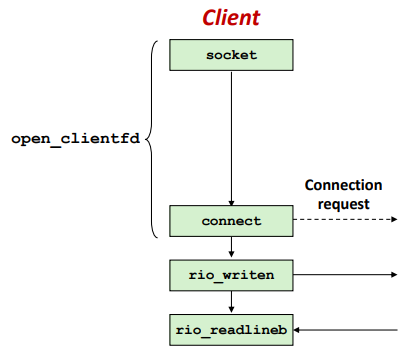
Call to connect returns
- 연결이 아직 수락되지 않았음에도 불구하고 서버측 TCP 관리자 대기열에 요청
- 위와 같은 현상을 "TCP listen backlog" 라고 한다.
Call to rio_writen returns
- 서버 측 TCP 관리자가 입력 데이터를 버퍼링한다.
Call to rio_readlineb blocks
- 서버에서의 읽을 내용을 아직 작성하지 않았다.
※ Fundamental Flaw of Iterative Servers

Iterative Server 를 해결하기 위한 해결책은 Concurrent Server 를 사용하는 것이다.
Concurrent Server 는 여러 개의 concurrent flows 를 사용하여 동시에 여러 클라이언트를 처리할 수 있다.
※ Approaches for Writing Concurrent Servers
서버가 여러 클라이언트를 동시에 처리할 수 있도록 허용하는 방법 3가지를 살펴보도록 하자.
1. Process-based
- 커널은 자동으로 여러개의 logical flows 를 interleave 한다. (즉, fork() 를 띄움)
- 각 flow 에는 고유한 개인 주소 공간이 있다. (서로 다른 process)
2. Event-based
- 프로그래머가 여러개의 logical flows 를 수동적으로 interleave 한다.
- 모든 flow 는 동일한 주소 공간을 공유한다. (서로 같은 process)
- I/O multiplexing 이라는 기술을 사용한다.
3. Thread-based
- 커널은 자동으로 여러개의 logical flows 를 interleave 한다.
- 각 flow 는 동일한 주소 공간을 공유한다.
- Process-based + Event-based 이다.
즉, Process-based 는 fork() 를 띄워서 여러 개의 프로세스로 작업을 처리한다.
그러나 Event-based 는 fork() 를 띄우지 않고 한 프로세스에 여러 개의 작업을 처리하도록 한다.
Event-based 는 게임에서 사용되는 방식이라고 한다.
Thread-based 는 쓰레드를 형성하여 여러 개의 쓰레드로 작업을 처리한다.
※ Approach #1 : Process-based Servers
Spawn separate process for each client

드디어 여러 개의 작업을 동시에 해결할 수 있게 되었다.
서버는 클라이언트의 connect 요청을 accept 할 때마다 fork() 를 호출하여 여러 개의 프로세스를 생성시켜서 작업을 동시에 처리할 수 있게 한다.
즉 fork 를 통해 클라이언트와 서버측의 connection establishment 가 각각 하게 됨으로써 작업을 동시에 처리한다.
※ Process-Based Concurrent Echo Server
#include "csapp.h"
void echo(int connfd);
void sigchld_handler(int sig) //line:conc:echoserverp:handlerstart
{
while (waitpid(-1, 0, WNOHANG) > 0)
;
return;
} //line:conc:echoserverp:handlerend
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
Signal(SIGCHLD, sigchld_handler);
listenfd = Open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen);
if (Fork() == 0) {
Close(listenfd); /* Child closes its listening socket */
echo(connfd); /* Child services client */ //line:conc:echoserverp:echofun
Close(connfd); /* Child closes connection with client */ //line:conc:echoserverp:childclose
exit(0); /* Child exits */
}
Close(connfd); /* Parent closes connected socket (important!) */ //line:conc:echoserverp:parentclose
}
}
/* $end echoserverpmain */
여러 개의 프로세스를 생성하여 echo 실행이 되도록 하는 코드이다.
우선 자식 프로세스이 종료될 때 sigchld_handler 함수를 통해 자식 프로세스를 reaping 하는 것으로 보인다.
그리고 connfd 값을 두 번 close 함으로써 open file table 에서 refcnt 값이 0 이 되도록 하는것이 핵심이다.
※ Concurrent Server: accept Illustated

1. 서버 블록이 수락 중, listening descriptor listenfd에서 연결 요청을 기다리고 있다.
2. 클라이언트가 connect 를 호출하여 연결 요청을 합니다.
3. 서버가 수락에서 connfd를 반환하고 클라이언트를 처리할 자식을 포크한다.
이제 clientfd와 connfd 사이에 연결이 설정되었다.
※ Process-based Server Execution Model

개별 하위 프로세스에 의해 처리되는 각 클라이언트로 두 사용자 간에 공유 상태가 없다. (서로 다른 프로세스)
부모 및 자식 모두 listenfd 및 connfd 복사본을 가지고 있다.
- 부모가 connfd 를 반드시 닫아야 한다.
- 자식은 listenfd 를 닫아야 한다.
※ Issues with Process-based Servers
수신 서버 프로세스에서 좀비 자식 프로세스를 수집해야 한다.
- memory leak 를 방지하기 위함
부모 프로세스는 connfd 복사본을 닫아야 한다.
- 커널은 각 소켓/열린 파일에 대한 참조 수를 유지한다.
- 포크 후, refcnt(connfd) = 2 이다.
- refcnt(connfd) = 0이 될 때까지 연결이 닫히지 않는다.
※ Pros and Cons of Process-based Servers
장점
(1) 여러 개의 connection 을 동시에 처리
(2) 클린 공유 모델
- descriptors (아니오)
- file tables (예)
- globall variables (아니오)
(3) 단순하고 간단하다.
단점
(1) 프로세스 제어를 위한 추가 오버헤드 발생
(2) 프로세스 간 데이터 공유 중요성
- IPC(프로세스 간 통신) 메커니즘 필요
- FIFO(이름 있는 파이프), 시스템 V 공유 메모리 및 세마포어
※ Approach #2 : Event-based Servers
서버는 active connection 집합을 유지 관리함
- connfd 의 배열로 관리
Repeat :
- 보류 중인 input을 가진 descriptor(connfd 또는 listenfd) 결정
- 예: select or epoll 함수 사용
- 보류 중인 input의 도착은 이벤트이다.
- listenfd에 input이 있으면 연결을 수락한다.
- 그리고 배열에 새로운 connfd를 추가한다.
- 보류 중인 입력으로 모든 connfd 서비스

※ I/O Multiplexec Event Processing
I/O Multiplexing
- select or epoll 함수를 사용하여 커널에 프로세스를 일시 중단하도록 요청하여 하나 이상의 I/O 이벤트가 발생한 후에 애플리케이션에 제어 권한을 반환한다.
Example
- {0, 4} 집합에 있는 descriptor 를 읽을 준비가 되면 반환
- {1, 2, 7} 집합에 있는 descriptor 를 쓸 준비가 되면 반환

※ Select.c
#include "csapp.h"
void echo(int connfd);
void command(void);
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr;
fd_set read_set, ready_set;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]); //line:conc:select:openlistenfd
FD_ZERO(&read_set); /* Clear read set */ //line:conc:select:clearreadset
FD_SET(STDIN_FILENO, &read_set); /* Add stdin to read set */ //line:conc:select:addstdin
FD_SET(listenfd, &read_set); /* Add listenfd to read set */ //line:conc:select:addlistenfd
while (1) {
ready_set = read_set;
Select(listenfd+1, &ready_set, NULL, NULL, NULL); //line:conc:select:select
if (FD_ISSET(STDIN_FILENO, &ready_set)) //line:conc:select:stdinready
command(); /* Read command line from stdin */
if (FD_ISSET(listenfd, &ready_set)) { //line:conc:select:listenfdready
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);
echo(connfd); /* Echo client input until EOF */
Close(connfd);
}
}
}
void command(void) {
char buf[MAXLINE];
if (!Fgets(buf, MAXLINE, stdin))
exit(0); /* EOF */
printf("%s", buf); /* Process the input command */
}
/* $end select */
client 와 통신할 수 있도록 하는 select.c 코드이다.
while(1) 문 전에 FD_ZERO, FD_SET 함수를 통해 read_set 을 다음과 같이 세팅할 수 있다.

while(1) 문에서의 코드중 ready_set = read_set 를 설정함으로써 read_set 은 이전에 저장했던 {0, 3} descriptor set 를 유지시키기 위함이다.
여러번의 실행 결과 알 수 있는 점은 다음과 같다.
1. Select 함수는 Input 또는 listen 을 대기하는 함수라고 볼 수 있다.
2. 서버 측 터미널에서 input 을 받을 경우 Select() 함수가 실행이 되면서 STDIN_FILENO 가 세팅이 되면서 자연스럽게 comand() 함수를 호출한다.
3. 클라이언트가 connection 을 요청할 경우 또한 Select() 함수가 실행이 되면서 listenfd 가 세팅이 되면서 Accept() 을 하여 받은 connfd 값을 통해 echo 가 가능하게 된다.
4. 단순히 하나의 클라이언트와의 통신을 위한 코드이다.
※ Issues with select.c
Blocking Problems
- 서버가 클라이언트에 연결되면 클라이언트가 연결의 끝을 닫을 때까지 입력 라인의 에코를 계속한다.
- 따라서 사용자가 표준 입력에 명령을 입력할 경우, 서버가 클라이언트와 함께 완료될 때까지 응답을 받지 못한다. (concurrent programming 이 안되는 문제점)
- 따라서, 서버 루프를 통해 매번 한 개의 텍스트 라인을 (최대) echo 하면서 더 미세한 세분성으로 다중화할 수 있는 방법이 필요하다.
※ I/O Multiplexed Event Processing
I/O multiplexing and event-driven programs
- I/O multiplexing 은 특정 이벤트의 결과로 흐름이 진행되는 동시 이벤트 기반 프로그램의 기반으로 사용될 수 있다.
Modeling logical flows as state machines
- state machines 은 상태, 입력 이벤트 및 입력 이벤트를 상태에 매핑하는 전환의 모음이다.
동시 이벤트 기반 에코 서버의 논리적 흐름에 대한 상태 시스템

#include "csapp.h"
typedef struct { /* Represents a pool of connected descriptors */ //line:conc:echoservers:beginpool
int maxfd; /* Largest descriptor in read_set */
fd_set read_set; /* Set of all active descriptors */
fd_set ready_set; /* Subset of descriptors ready for reading */
int nready; /* Number of ready descriptors from select */
int maxi; /* Highwater index into client array */
int clientfd[FD_SETSIZE]; /* Set of active descriptors */
rio_t clientrio[FD_SETSIZE]; /* Set of active read buffers */
} pool; //line:conc:echoservers:endpool
/* $end echoserversmain */
void init_pool(int listenfd, pool *p);
void add_client(int connfd, pool *p);
void check_clients(pool *p);
/* $begin echoserversmain */
int byte_cnt = 0; /* Counts total bytes received by server */
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr;
static pool pool;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]);
init_pool(listenfd, &pool); //line:conc:echoservers:initpool
while (1) {
/* Wait for listening/connected descriptor(s) to become ready */
pool.ready_set = pool.read_set;
pool.nready = Select(pool.maxfd+1, &pool.ready_set, NULL, NULL, NULL);
/* If listening descriptor ready, add new client to pool */
if (FD_ISSET(listenfd, &pool.ready_set)) { //line:conc:echoservers:listenfdready
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); //line:conc:echoservers:accept
add_client(connfd, &pool); //line:conc:echoservers:addclient
}
/* Echo a text line from each ready connected descriptor */
check_clients(&pool); //line:conc:echoservers:checkclients
}
}
/* $end echoserversmain */
/* $begin init_pool */
void init_pool(int listenfd, pool *p)
{
/* Initially, there are no connected descriptors */
int i;
p->maxi = -1; //line:conc:echoservers:beginempty
for (i=0; i< FD_SETSIZE; i++)
p->clientfd[i] = -1; //line:conc:echoservers:endempty
/* Initially, listenfd is only member of select read set */
p->maxfd = listenfd; //line:conc:echoservers:begininit
FD_ZERO(&p->read_set);
FD_SET(listenfd, &p->read_set); //line:conc:echoservers:endinit
}
/* $end init_pool */
/* $begin add_client */
void add_client(int connfd, pool *p)
{
int i;
p->nready--;
for (i = 0; i < FD_SETSIZE; i++) /* Find an available slot */
if (p->clientfd[i] < 0) {
/* Add connected descriptor to the pool */
p->clientfd[i] = connfd; //line:conc:echoservers:beginaddclient
Rio_readinitb(&p->clientrio[i], connfd); //line:conc:echoservers:endaddclient
/* Add the descriptor to descriptor set */
FD_SET(connfd, &p->read_set); //line:conc:echoservers:addconnfd
/* Update max descriptor and pool highwater mark */
if (connfd > p->maxfd) //line:conc:echoservers:beginmaxfd
p->maxfd = connfd; //line:conc:echoservers:endmaxfd
if (i > p->maxi) //line:conc:echoservers:beginmaxi
p->maxi = i; //line:conc:echoservers:endmaxi
break;
}
if (i == FD_SETSIZE) /* Couldn't find an empty slot */
app_error("add_client error: Too many clients");
}
/* $end add_client */
/* $begin check_clients */
void check_clients(pool *p)
{
int i, connfd, n;
char buf[MAXLINE];
rio_t rio;
for (i = 0; (i <= p->maxi) && (p->nready > 0); i++) {
connfd = p->clientfd[i];
rio = p->clientrio[i];
/* If the descriptor is ready, echo a text line from it */
if ((connfd > 0) && (FD_ISSET(connfd, &p->ready_set))) {
p->nready--;
if ((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0) {
byte_cnt += n; //line:conc:echoservers:beginecho
printf("Server received %d (%d total) bytes on fd %d\n",
n, byte_cnt, connfd);
Rio_writen(connfd, buf, n); //line:conc:echoservers:endecho
}
/* EOF detected, remove descriptor from pool */
else {
Close(connfd); //line:conc:echoservers:closeconnfd
FD_CLR(connfd, &p->read_set); //line:conc:echoservers:beginremove
p->clientfd[i] = -1; //line:conc:echoservers:endremove
}
}
}
}
/* $end check_clients */

구조체 pool 을 선언함으로써 concurrent programming 이 가능하게 되었다.
우선 init_pool() 함수를 통해서 listenfd 를 인자로 하여 pool 을 초기화 하였다.
init_pool() 함수는 자세히 보면 FD_ZERO(), FD_SET() 함수를 호출하는 과정에서 STDIN_FILENO 에 대한 FD_SET() 을 해주지 않았다. (즉, 클라이언트의 connection 만 처리하며 서버 터미널에서 입력을 하지 않도록 설정)
while(1) 루프에서는 동일하게 pool.ready_set 을 할당해주고 Select 함수를 호출한 값을 pool.nready 에 할당해준다.
그 후에 listenfd 즉, 클라이언트가 connection 하였다면 Accept() 하여 얻은 connfd 에 대해서 add_client() 함수에 connfd 를 인자로 하여 넘겨준다.
add_client() 함수에서는 pool 에다가 연결된 descriptor 을 추가해주는 작업을 진행해주고 Rio_readinitb() 함수를 호출하여 클라이언트가 인자값 connfd 을 통해 서로 연결이 되도록 해주었다.
그리고 FD_SET() 함수를 통해 connfd 값을 read_set 에 설정해주었다.
check_clients() 함수는 concurrent programming 의 핵심이 되는 부분으로 add_client() 함수에서 FD_SET() 함수를 통해 connfd 값을 설정해준 client 들을 탐색하여 Rio_readlineb() 함수를 통해 클라이언트측에서 입력한 문자열들을 읽어들이고 Rio_writen() 함수를 통해서 connfd 를 file descriptor 로 설정해둠으로써 클라이언트 측에서 읽어들인 문자열 buf 를 출력해준다.
그리고 클라이언트가 종료하게 되면 Close() 함수를 호출하여 connfd 값을 해제하고 FD_CLR() 함수를 통해 현재 read_set 의 connfd 으로 마킹된 부분을 없애준 후에 해당 클라이언트를 -1 으로 마킹하여 클라이언트가 사라졌음을 암시하도록 설정한다.
※ Pros and Cons of Event-based Servers
장점
(1) 하나의 논리적 제어 흐름 및 주소 공간
(2) 디버거로 단일 단계를 수행할 수 있다.
(3) 프로세스 또는 스레드 제어 오버헤드가 없다.
- 고성능 웹 서버 및 검색 엔진(예: Node.js, nginx, Tornado)을 위한 선택 설계
단점
(1) 프로세스 또는 스레드 기반 설계보다 훨씬 더 복잡하다.
(2) 세분화된 동시성 제공이 어려움
- 예: 부분 HTTP 요청 헤더를 처리하는 방법
(3) 멀티코어를 활용할 수 없음
- 단일 제어 스레드
※ Approach #3: Threaded-based Servers
Process-based 과 매우 유사해보이지만 프로세스 대신 쓰레드를 사용한다는 점이다.
즉, fork() 를 통해 process 를 띄우는 기반이 아닌 pthread_create() 를 통해 thread 를 띄우는 기반이다.
※ Traditional View of a Process
Process = process context + code, data, and stack

※ Alternate View of a Process

여기서 핵심은 쓰레드는 Code, data, 그리고 kernel context 를 공유하지만 stack 및 thread context 는 각 쓰레드 별로 고유하게 가지고 있으며 공유하지 않는다.
※ A Process with Multiple Threads
프로세스와 여러 스레드를 연결할 수 있다.
- 각 스레드에는 고유한 논리적 제어 흐름이 있다.
- 각 스레드는 동일한 코드, 데이터 및 커널 컨텍스트를 공유한다.
- 각 스레드에는 로컬 변수에 대한 자체 스택이 있다.
- 다른 스레드로부터 보호되지 않음
- 각 스레드에는 자체 스레드 ID(TID)가 있다.

※ Logical View of Threads
프로세스와 연결된 스레드가 피어 풀을 형성한다. (트리 계층을 형성하는 프로세스와 다르게)

※ Concurrent Threads
두 스레드의 흐름이 시간적으로 겹치는 경우 두 스레드가 concurrent 하게 발생한다.
그렇지 않은 경우 sequential 이다.
아래 사진을 보도록 하자.

이 경우 concurrent 인 경우는 A&B, A&C 이며 sequential 인 경우는 B & C 이다.
다음 사진은 Single core 프로세스일 경우와 Multi-Core 프로세스일 경우 쓰레드가 실행되는 사진이다.

왼쪽 사진은 단일 코어 프로세스이며 오른쪽 사진은 멀티 코어 프로세스인 경우다.
즉, 단일 코어 프로세스인 경우는 time slicing 을 통해 parallelism 을 활성화 시키며 멀티 코어 프로세스일 경우 실제의 parallelism 을 활성시킨 경우이다.
※ Threads vs. Process
스레드 및 프로세스 유사성
- 각각의 논리적 제어 흐름이 있다.
- 각각 다른 코어와 동시에 실행 가능(다른 코어로 실행 가능)
- 각각 컨텍스트가 전환된다.
스레드 및 프로세스 차이점
- 스레드는 모든 코드 및 데이터를 공유한다(스택 제외).
- 프로세스(일반적으로)는 그렇지 않다.
- 스레드는 프로세스보다 다소 저렴하다.
- 프로세스 제어(생성 및 수확)는 스레드 제어보다 2배 더 비싸다.
- 리눅스 번호:
- 최대 20K 사이클로 프로세스 생성 및 재확보
- 스레드를 생성하고 재확보하는 데 최대 10K 주기(또는 그 이하)
※ Posix Threads (Pthreads) Interface
Pthreads: C 프로그램의 스레드를 조작하는 최대 60개의 기능을 위한 표준 인터페이스이다.
- 스레드 생성 및 수집
- pthread_create()
- pthread_join()
- 스레드 ID 결정
- pthread_self()
- 스레드 종료
- pthread_cancel()
- pthread_exit()
- exit()[모든 스레드를 종료]
- 공유 변수에 대한 액세스 동기화
- pthread_mutex_init
- pthread_mutex_[un]lock


※ Thread-Based Concurrent Echo Server

치명적인 race 를 피하기 위해 필요한 malloc 연결 descriptor 이다.
이 코드에 치명적인 점이 있는데 connfdp 는 포인터 값이다.
즉, 동적할당을 통해 heap 영역에 숫자가 마킹이 되는 그런 형태인데 pthread_create() 를 연속으로 2번 하여 peer1, peer2 가 동시에 connfdp 를 공유하는 형태라고 가정해보자.
즉, peer1 은 connfd = 10 을 기대하고 있고 peer2 은 connfd = 11 을 기대하고 있지만 peer1, peer2 둘 다 connfd = 11 값을 공유하게 됨으로써 이전의 connfdp 값 10 은 사라지게 된다.

스레드를 "deatached" 모드로 실행한다.
- 다른 스레드와 독립적으로 실행
- 종료 시 자동으로(커널에 의해) reaping 됨
connfd 를 유지하기 위해 할당된 사용 가능한 저장소이다.
connfd 를 닫는건 중요하다. (memory leacking 을 방지하기 위함)
※ Thread-based Server Execution Model
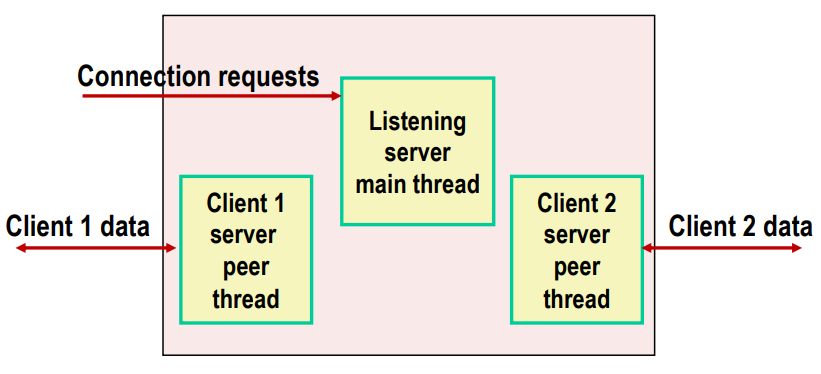
개별 피어 스레드에 의해 처리되는 각 클라이언트
스레드는 TID 를 제외한 모든 프로세스 상태를 공유한다.
각 스레드에는 로컬 변수에 대한 개별 스택이 있다.
※ Issues With Thread-Based Servers
메모리 누수를 방지하기 위해 "detached" 를 실행해야 한다.
- 스레드는 언제든지 조인할 수 있거나 분리되어 있다.
- 결합 가능한 스레드는 다른 스레드에 의해 수확되고 소멸될 수 있다.
- 메모리 리소스를 확보하려면 pthread_join 를 사용하여 리핑해야 한다.
- 분리된 스레드는 다른 스레드에 의해 회수되거나 폐기될 수 없다.
- 종료 시 리소스가 자동으로 획득됨
- 기본 상태는 joinable
- pthread_detach(pthread_self()) 를 사용하여 분리시킨다.
의도하지 않은 공유가 발생하지 않도록 주의해야 한다.
- 예를 들어, 주 스레드의 스택에 포인터 전달
- Pthread_create(&tid, NULL, thread, (void *)&connfd);
※ Pros and Cons of Thread-Based Designs
장점
(1) 스레드 간에 데이터 구조를 쉽게 공유할 수 있다.
- 예: 로깅 정보, 파일 캐시
(2) 스레드는 프로세스보다 효율적이다.
단점
(1) 의도하지 않은 공유로 인해 미묘하고 재현하기 어려운 오류가 발생할 수 있다.
- 데이터 공유의 용이성은 스레드의 최대 강점과 최대 약점이다.
- 어떤 데이터가 공유되고 어떤 개인 데이터가 공유되었는지 알 수 없음
- 테스트로 감지하기 어려움
- 나쁜 race 결과가 나올 확률은 매우 낮지만 0의 확률은 아니다.
'학교에서 들은거 정리 > 시스템프로그래밍' 카테고리의 다른 글
| Synchronization : Advanced (0) | 2022.05.12 |
|---|---|
| Synchronization: Basics (0) | 2022.04.28 |
| Network Programming: Part II (0) | 2022.04.08 |
| Network Programming: Part I (0) | 2022.04.01 |
| System-Level I/O (0) | 2022.04.01 |



