
mojo's Blog
Malloc 본문
※ Keeping Track of Free Blocks
Method 1: 길이를 사용한 implicit list 으로 모든 블록을 연결한다.

Method 2: 포인터를 사용하는 free blocks 중에 explicit list 이다.
Method 3: Segregated free list
- 다양한 크기 클래스에 대한 서로 다른 free lists
Method 4: 크기별로 정렬된 Blocks
- 각 free 블록 내에 포인터가 있는 균형 잡힌 트리(Red-Black tree)와 key로 사용된 길이를 사용할 수 있다.
1번 방법 같은 경우는 포인트된 모든 영역을 전부 스캔해야하는 점에서 시간적인 문제가 존재한다.
2번 방법 같은 경우는 free 된 영역만을 scan 하기 때문에 시간적인 문제는 줄지만
free 된 영역을 포인트할 수 있는 추가 포인터가 선언이 되기 때문에 그로 인한 공간적인 문제가 존재한다.
※ Method 1 : Implicit List
각 블록에 대해 크기와 할당 상태가 모두 필요하다.
- 이 정보를 두개의 word로 저장할 수 있다 -> wasteful
Standard trick
- 블록이 정렬된 경우, 일부 하위 주소 비트는 항상 0 이다.
- 항상 0 비트를 저장하는 대신, allocated/free 플래그로 사용한다.
- size word 를 읽을 때, 이 비트를 masking 해야 한다.

두 개의 word 를 통해서 size와 allocated/free 상태를 확인하는 방법이 있긴하다.
그러나 이러한 방법은 두 개의 word 즉, metadata 를 8 byte 로 잡기 때문에 사이즈가 큰 문제점이 있다. (word size를 4 byte로 가정)
따라서 약간의 트릭을 통해 bitmask 를 통해서 size와 allocated/free 상태를 확인할 수 있으며,
단 하나의 word 를 통해서 확인이 가능하게 된다.
Optional padding 이란 word alignment 를 준수하기 위해 만들어진 것이라고 보면 될 것 같다.
예를 들어서 word 사이즈를 4 byte 라고 할 때, payload 가 80 byte라고 가정해보자.
그렇다면 size 에 대한 word 1개, payload 에 대한 word 20개가 존재하게 된다.
이때 Double-word aligned 를 준수할 때 8 byte 단위로 alignment 를 준수해야 한다고 하면,
총 84 byte 으로 4 byte 가 모자라기 때문에 나머지 4 byte를 padding 을 통해 word alignment 를 지킬 수 있게 된다.
따라서 word 22개(size + payload + optional padding) 으로 구성된다.
※ Detailed Implicit Free List Example
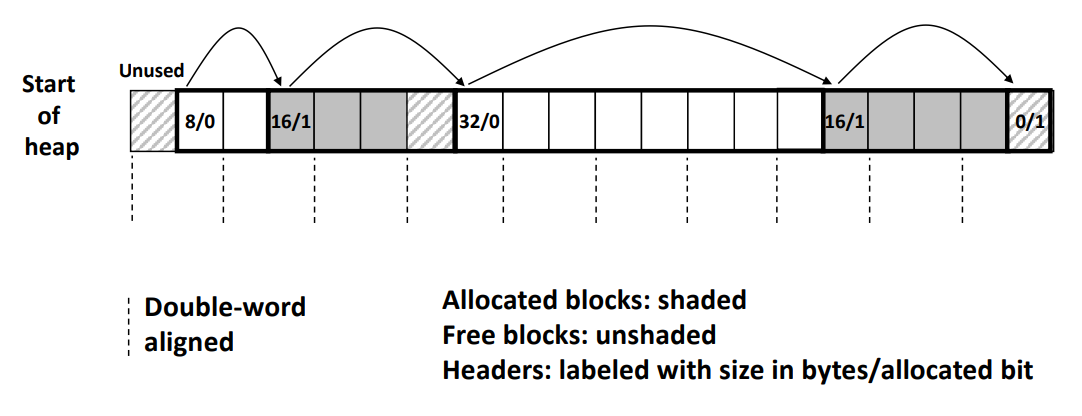
위 그림은 여러 사이즈의 할당되거나 free 된 블럭들로 구성된 것으로 보인다.
우선, word size 는 4 byte 인 것을 알 수 있으며 Double-word aligned 은 8 byte 단위인 것으로 알 수 있다.
위 그림에서 왼쪽 블럭에서 검은 블럭으로 총 16 byte로 구성된 것을 보면 원래는 12 byte 이지만,
8 byte 단위로 word alignment 를 지켜야 하기 때문에 나머지 4 byte가 padding 이 붙여진 것으로 짐작할 수 있다.
따라서 Implict Free List 의 장단점은 다음과 같다.
- 장점 : 간단하다.
- 단점 : 모든 작업을 수행하려면 블럭이 할당되거나 free 된 list 를 검색해야 한다.
※ Implicit List : Finding a Free Block
First fit :
- 처음부터 list를 검색 후, 다음 항목에 적합한 첫 번째 free 블록을 선택한다.
- 총 블록 수(allocated and free)에 선형 시간이 걸릴 수 있다.
- 실제로 list의 시작 부분에 "splinters"이 발생할 수 있다. (splinter : 분할)
p = start;
while ((p < end) && \\ not passed end
((*p & 1) || \\ already allocated
(*p <= len))) \\ too small
p = p + (*p & -2); \\ goto next block (word addressed)Next fit :
- first fit 처럼 이전 검색이 완료된 곳에서 시작하는 검색 list
- first fit 보다 빠른 경우가 많다 (도움이 되지 않는 블록을 다시 검색하지 않음)
- 일부 연구를 통해 fragmentation이 더 나쁘다는 것을 확인
Best fit :
- list를 검색하고, 가장 적합한 빈 블록을 선택한다. (가장 적은 바이트로 남은 곳)
- fragment 를 작게 유지하므로 일반적으로 메모리 활용률 향상
- 일반적으로 첫 번째 장착보다 느리게 실행됨
first bit 같은 경우는 처음부터 무식하게 찾기 때문에 많은 시간이 소요될 것으로 보인다.
next bit 은 그나마 first bit 의 시간적인 요소를 완화하기 위해 이전에 발견한 free 영역을 시작으로 하기 때문에 모든 경우를 탐색하지 않는 장점이 있다.
그러나 이렇게 할 경우 external fragmentation 문제점이 있다.
external fragmentation 이란 메모리 영역에 할당된 영역 사이에 약간의 free 영역이 존재하는데,
이러한 영역들로 인해 메모리 할당을 연속적으로 배치할 수 없는 경우를 의미한다.
best fit 은 next bit의 external fragmentation 을 최소화하기 위해 나타난 기법으로
가장 적합한 free 영역을 찾아서 해당 영역을 할당하는 기법이다.
그러나 가장 적합한 free 영역을 찾기 위해서 모든 free 영역을 scanning 해야 한다는 점에서
많은 시간이 소요될 것으로 보이지만 메모리 효율성은 뛰어난 것을 알 수 있다.
※ Implict List : Allocating in Free Block
Allocating in a free block : splitting
할당된 공간이 free 공간보다 작을 수 있으므로 블록을 분할할 수 있다.
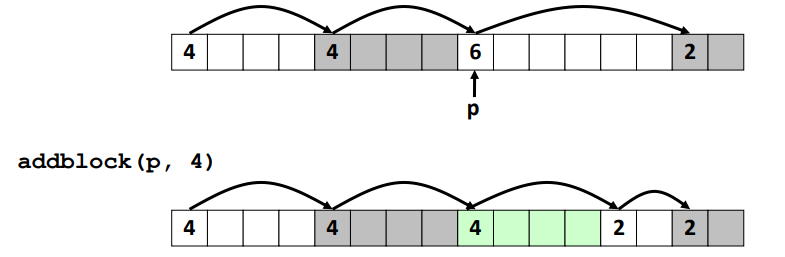
void addblock(ptr p, int len) {
int newsize = ((len + 1) >> 1) << 1; // round up to even
int oldsize = *p & -2; // mask out low bit
*p = newsize | 1; // set new length
if (newsize < oldsize)
*(p+newsize) = oldsize - newsize; // set length in remaining
} // part of block
위 코드를 분석해보면 ...
(1) newsize 는 len 값이 4일 경우와 5일 경우를 생각해보자.
- len = 4 : len + 1 은 5이므로
- len = 5 : len + 1 은 6이므로
즉, 짝수일 경우는 그대로이며 홀수일 경우에는 짝수로 올림해주는 것으로 알 수 있다.
(2) oldsize 는 -2 와 & 연산을 취하는데 -2 는 LSB 값을 제외한 모든 비트가 1이므로
LSB 를 제외한 모든 비트를 masking 하는 것으로 볼 수 있다.
따라서 oldsize = *p & -2 = 6 & -2 =
(3) *p 는 block 에 대한 size 를 담고 있는 영역을 포인트하기 때문에 addblock(p, 4) 를 호출하게 되면
*p = 4 | 1 = 5 가 할당되게 된다.
이때, LSB에 1이 들어가게 됨으로써 블럭이 할당되게 되는 것을 알 수 있다.
(4) newsize값이 oldsize보다 작을 경우, *(p + newsize) = oldsize - newsize 를 할당한다고 한다.
즉, free 공간에 대한 size는 oldsize이고 할당하고자 하는 size는 newize 이기 때문에
newsize 가 더 작을 경우 나머지 free 공간에 대한 metadata 를 update 해줘야 한다.
따라서 newsize 값은 4, oldsize 값은 6이기 때문에 *(p + 4) = 6 - 4 = 2 값을 할당하게 된다.
※ Implicit List : Freeing a Block
Simplest implementation :
"allocated" 플래그만 삭제하면 된다.
void free_block(ptr p) { *p = *p & -2 }
하지만 "false fragmentation" 으로 이어질 수 있다.

사용 가능한 공간이 충분하지만 allocator 가 할당할 수 있는 공간을 찾을 수 없다.
※ Implicit List : Coalescing
free 한 경우, next/previous block 과 결합한다.(Coalesce)
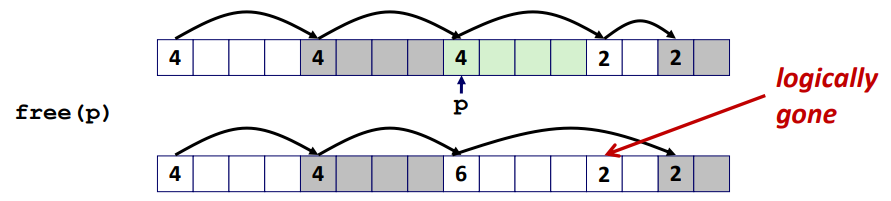
void free_block(ptr p) {
*p = *p & -2; // clear allocated flag
next = p + *p; // find next block
if ((*next & 1) == 0)
*p = *p + *next; // add to this block if
} // not allocated
위 코드의 문제점은 어떻게 이전 블록과 합칠 수 있을지에 대한 issue 가 있다.
우선 코드를 분석해보자.
(1) *p = *p & -2; 를 통해서 현재 *p = 4 이므로 *p = *p & -2 =
(2) next = p + *p; 는 현재 주소 p에다가 *p를 더하므로 next block 임을 짐작할 수 있다.
이때 *p = 4 이므로, next = p + 4 이다.
(3) *next & 1 값이 0일 경우, *p = *p + *next; 를 실행한다.
즉, next가 포인트하고 있는 값은 2이기 때문에 *next & 1 = 2 & 1 = 0 이다.
따라서 *p = *p + *next = 4 + 2 = 6 으로 위 사진과 동일하게 되었다.
※ Implicit List : Bidirectional Coalescing
Boundary tags [Knuth73]
- 사용 가능한 블록의 "bottom"(끝)에 size/allocated word를 복제한다.
- "list"를 뒤로 이동할 수 있지만, 그만큼 추가 공간이 필요하다.
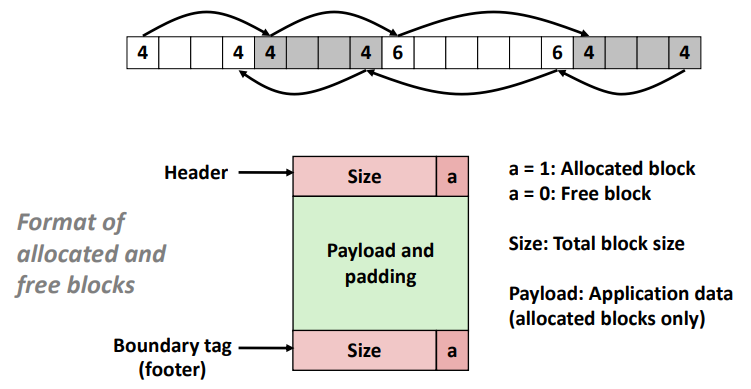
위와 같이 list를 뒤로 탐색할 수 있는 추가 공간을 마련하게 된다면,
위에서 살펴본 coalescing 사진에서 할당된 블럭을 free 할 때 정상적으로 처리할 수 있게 된다.
그러나, internal fragmentation 이 발생하게 되는 단점이 존재한다. (pointer 하나를 더 차지하는 셈이니깐)
※ Constant Time Coalescing
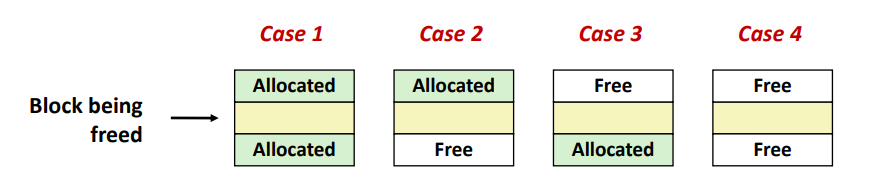
네 가지 케이스가 존재한다.
위 사진에서 초록색 영역을 Allocated block, 노란색 영역을 free 될 영역,
흰 영역을 free 영역이라고 할 때 어떻게 coalescing 하는지를 살펴보도록 한다.
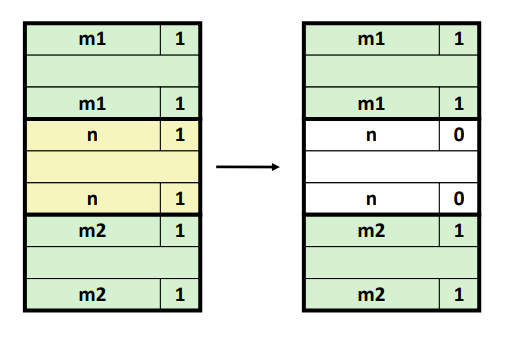
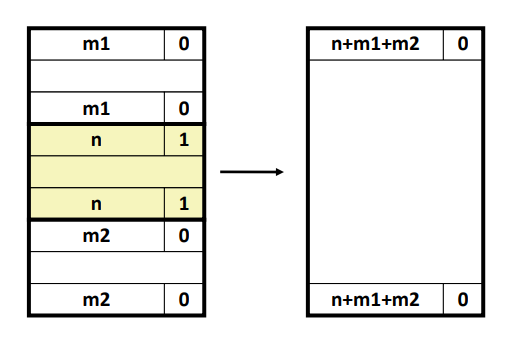
- case 1 : 양 쪽이 allocated 한 상황이다.
이 경우에는 coalescing 할 필요가 없으며 해당 블럭을 free 하면서 free bit 만 변경해주면 된다.
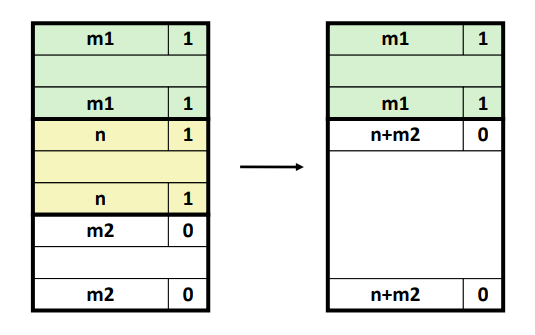
- case 2, 3: 한 쪽이 free 한 상황이다.
이 경우에는 해당 블럭을 free 하여 free bit 로 변경하고 free 블럭과 coalescing 을 해준다.
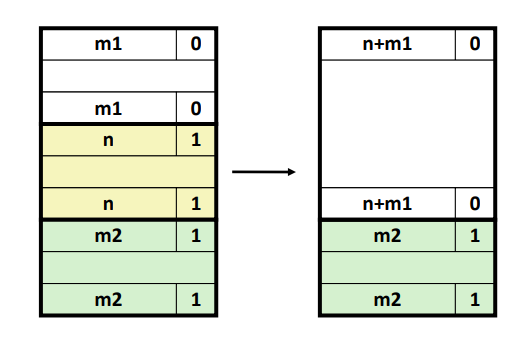
- case 4 : 양 쪽이 free 한 상황이다.
이 경우에는 해당 블럭을 free 하고 양 쪽에 있는 free 블럭과 coalescing 을 해준다.
※ Summary of key Allocator Policies
Placement policy :
- first-fit, next-fit, best-fit 등이 있다.
- throughput, fragmentation 이 둘의 trade off 이 존재한다.
Splitting policy :
- 언제 우리가 free 블록을 나눠야 하는지?
- 얼마나 많은 internal fragmentation을 부담할 의향이 있는지? (boundary tag 를 추가할 것인지)
Coalescing policy :
- Immediate coalescing : 비어 있을 때마다 병합
- Deferred coalescing : 필요할 때까지 병합을 연기하여 free 성능을 향상시킵니다.
- malloc에 대한 free list를 검색할 때 병합
- external fragmentation의 양이 특정 임계값에 도달하면 병합
처리량을 내/외부 단편화 관점으로 생각해보면 다음과 같다.
- 처리량과 내부 단편화 : 실제 저장할 data 에 대한 metadata 의 용량이 커질수록 처리량이 좋아지지만, 그로 인해 내부 단편화가 커지며, 내부 단편화를 줄이게 된다면 free 블럭간의 coalescing 을 할 때 issue와 처리량이 떨어진다.
- 처리량과 외부 단편화 : best-fit 을 통해 외부 단편화를 줄일 수 있지만 모든 block들을 탐색해야 하므로 처리량이 떨어지며, next-fit 을 통해 처리량을 높일 수 있지만 외부 단편화가 높아진다.
※ Explicit Free List
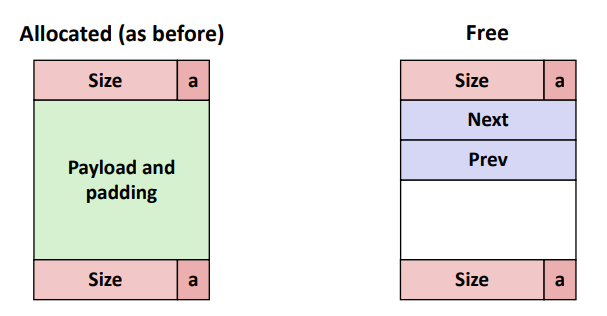
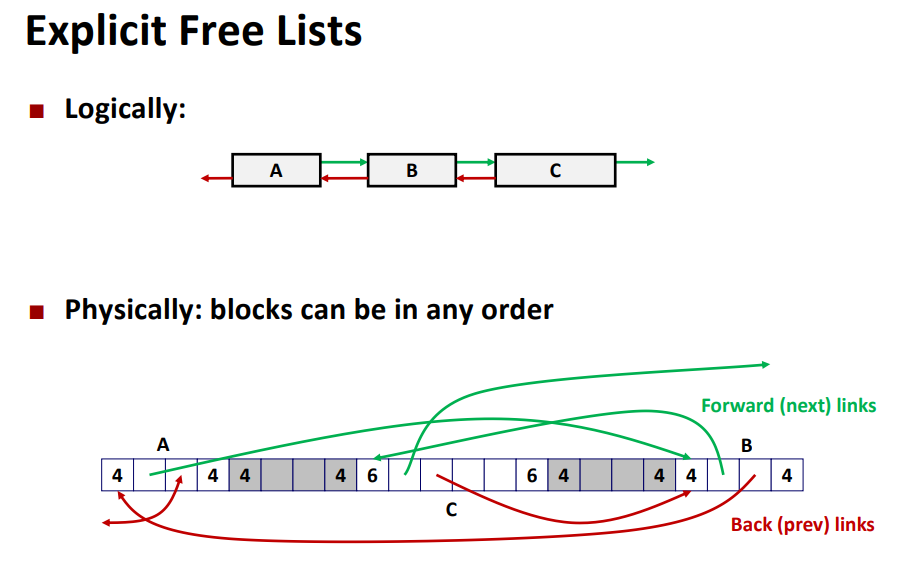
모든 블록(allocated/free)이 아닌 free 블록 리스트를 유지 관리하는 방법
- "next" free 블록은 어디에나 있을 수 있다.
- 따라서 크기뿐만 아니라 forward/backward pointer를 저장해야 한다.
- coalescing 을 위해 여전히 boundary tag 가 필요함
- free 블록만을 추적해서 payload 영역을 사용할 수 있다.
implicit free list 는 모든 block 을 탐색해야 한다는 점에서 시간 효율성이 떨어지지만,
best-fit 을 통해 최적의 free 블럭을 찾아내서 할당하게 될 경우 공간 효율성이 높다.
반면에 explicit free list 는 free block 만을 탐색한다는 점에서 시간 효율성이 높지만,
free 블럭을 가르키는 포인터를 둬야 한다는 점에서 공간 효율성이 떨어진다.
※ Allocating From Explicit Free Lists
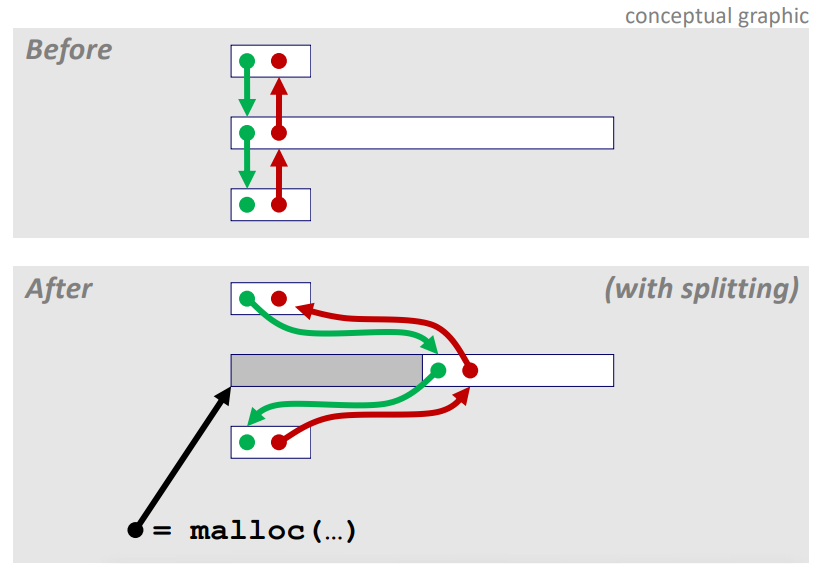
heap 영역의 첫 영역에 malloc 을 하게 될 경우 파라메터 길이만큼 forward/backward pointer 를 이동시켜서
이전 free 블럭와 다음 free 블럭과의 point 를 재설정한다.
※ Freeing With Explicit Free Lists
Insertion policy : free 리스트 내에 어디에 freed block 을 새롭게 놓을 것인지?
LIFO policy
- free list 시작 부분에 freed 블록을 삽입한다.
- Pro: 단순하며 상수 시간이 소요
- Con: 연구를 통해 fragmentation이 address ordered 방식보다 더 나쁜 것이 제안됨
Address-ordered policy
- free list에서 free 블록은 항상 주소 순서를 기준으로 삽입한다.
- addr(prev) < addr(cur) < addr(next)
- Pro: 연구를 통해 LIFO 보다 fragmentation 이 낮다는 것이 제안됨
- Con: 검색을 요구함
보통 LIFO policy 방식을 많이 사용한다고 한다.
단편화에 대한 issue 가 존재하지만 단순하며 constant 시간이 소요된다는 메리트가 있다.
즉, 개발자들은 시간 효율성을 더 중점으로 봐서 LIFO policy 방식을 사용한 것 같다.
※ Freeing With a LIFO Policy
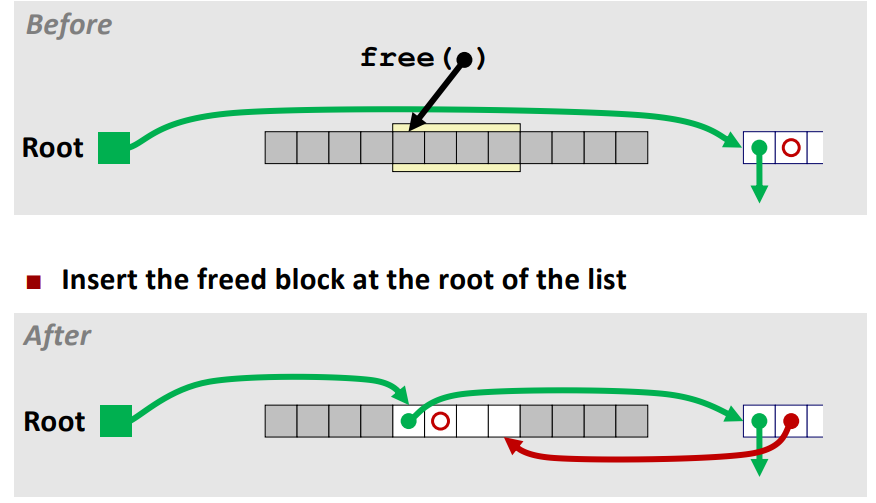
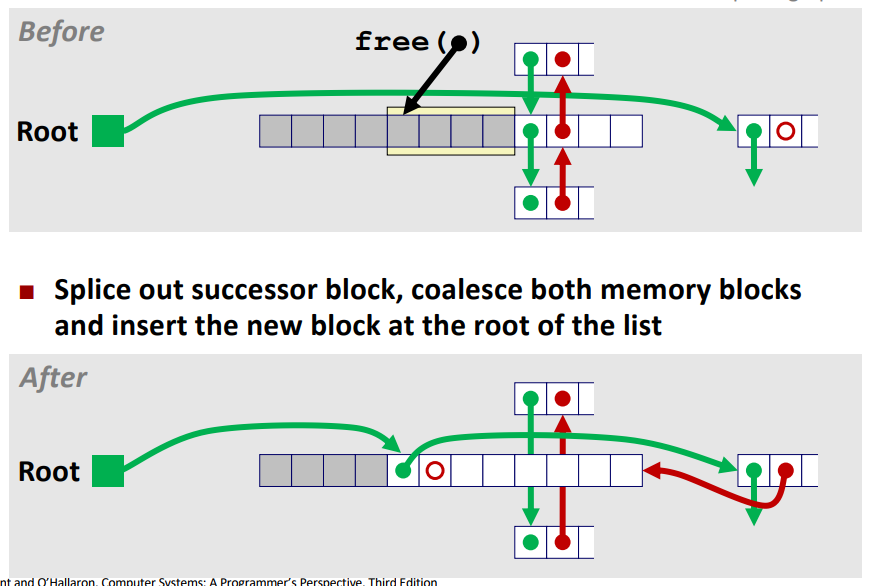
case 1 : 왼쪽 케이스는 free 하고자 하는 할당된 영역의 prev/next 블록이 전부 할당된 케이스이다.
이 경우에는 해당 블럭을 free 시키고 root가 해당 영역을 point 하도록 하며
이전에 root 가 가르키던 free 영역의 prev pointer 가 free 한 영역을 point 하도록 한다.
case 2 : 오른쪽 케이스는 free 하고자 하는 할당된 영역의 prev 블록은 할당되며 next 블록은 free 된 케이스이다.
이 경우에는 왼쪽 케이스와 동일하게 처리를 해주면서
free 영역의 next 블록에 free 된 블럭의 next, prev pointer 를 위 사진과 같이 갱신해줘야 한다.
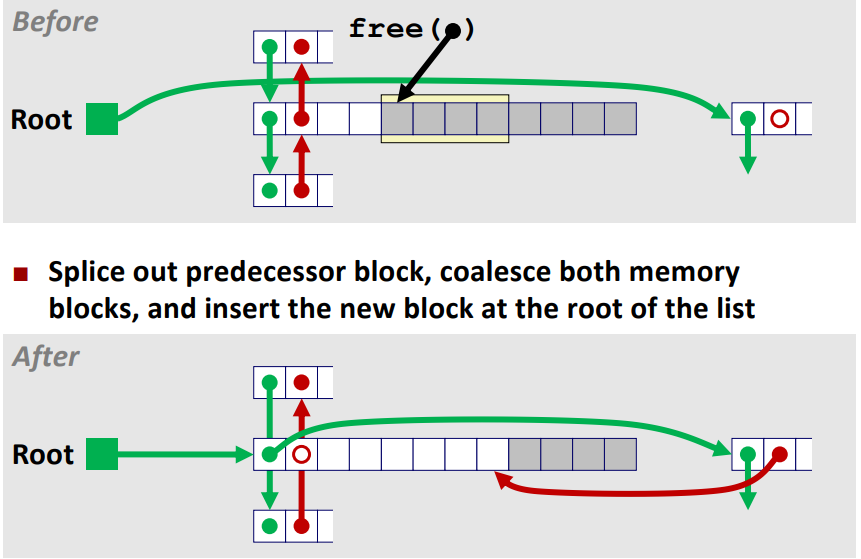
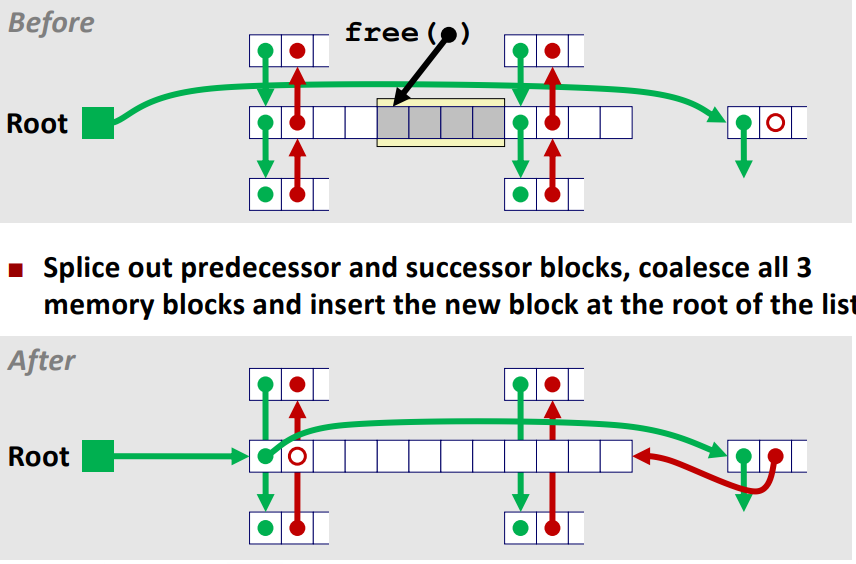
case 3 : 왼쪽 케이스는 free 하고자 하는 할당된 영역의 prev 블록은 free 영역이며 next 블록은 할당된 영역이다.
이번에는 prev 블록에 free 블록이 존재하므로 해당 영역에 point 하는 것이 아닌
prev 블록의 next pointer 를 가르키도록 하는 것이 핵심이다.
또한 root 가 가르켰던 free 블록의 prev 포인터를 현재 free 한 영역의 끝부분을 point 하도록 하면서
case 2와 동일하게 free 할 영역의 prev 블록에 free 된 블럭의 next, prev pointer 를 위 사진과 같이 갱신해줘야 한다.
case 4 : case 2, 3 를 합친 케이스라고 볼 수 있으며 case 3 과 같은 매커니즘으로 포인터를 처리하면서
free 할 블록의 next 블록 또한 free 영역이므로 해당 영역의 next, prev pointer 또한 위 사진과 같이 갱신해주면 된다.
※ Explicit List Summary
Comparison to implicit list :
- 할당은 모든 블록 대신 free 블록 수로 표시되는 선형 시간이다.
- 대부분의 메모리가 꽉 찼을 때 훨씬 더 빠름
- 블록을 목록 안팎으로 분할해야 하므로 allocate, free 작업이 약간 더 복잡하다.
- 링크를 위한 추가 공간(각 블록에 대해 2개의 word 필요)
- 이로 인해 internal fragmentation 증가
Linked list 의 가장 일반적인 사용은 segregated free list 와 함께 사용됩니다.
- 크기가 서로 다른 클래스 또는 서로 다른 개체 유형에 대해 여러 개의 연결된 목록 유지
※ Segregated List (Seglist) Allocators
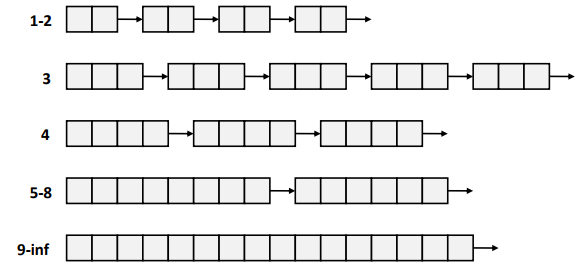
블록의 각 크기 클래스에는 고유한 사용 가능한 리스트가 있다.
종종 각 작은 크기에 대해 별도의 클래스를 가지며 더 큰 크기의 경우 각 2-power 크기에 대한 하나의 클래스를 가진다.
특정 크기 클래스에 대해 각각에 대해 free list 에 대한 배열을 지정한다.
크기 n의 블럭을 할당하려면 :
- m > n 크기의 블록에 대한 적절한 free list를 검색
- 적절한 블록이 발견될 경우 블록을 분할하고 해당 list에 fragment를 배치
- 블록을 찾을 수 없으면 다음 큰 클래스를 시도한다.
- 블록을 찾을 때까지 반복한다.
블록을 찾을 수 없는 경우:
- OS에서 추가 힙 메모리를 요청 (sbrk() 사용)
- 이 새 메모리에서 n바이트 블록을 할당
- 나머지를 가장 큰 크기 클래스에 single free 블록으로 배치한다.
블록을 free 하려면 :
- Coalesce 하여 적절한 list 에 배치한다.
seglist allocators 의 장점
- 높은 처리량을 가진다.
- power-of-two size class 에 대한 로그 시간 소요
- 메모리 활용도가 향상된다.
- 분리된 free list의 first-fit 검색은 전체 heap에 대한 best-fit 과 유사하다.
- 극단적인 경우, 각 블럭에 고유한 크기 클래스를 지정하는 것은 best-fit 과 같다. (완전 탐색으로 오랜 시간 소요)
메모리 활용도가 높은 이유는 결국 가장 블록 사이즈가 적은 클래스부터 접근하기 때문이다.
'학교에서 들은거 정리 > 시스템프로그래밍' 카테고리의 다른 글
| malloc 구현 코드 리뷰 (2) | 2022.05.31 |
|---|---|
| Garbage collection (0) | 2022.05.27 |
| Dymaic Memory Allocation (0) | 2022.05.22 |
| Parallelism (0) | 2022.05.17 |
| Synchronization : Advanced (0) | 2022.05.12 |



