
mojo's Blog
Semantic Analysis 본문
Semantic Analysis:
● Syntax tree와 symbol table을 이용하여 소스 프로그램이 언어 정의에 의미적으로 (semantically)
일치하는지 검사
● identifier가 프로그램 내의 수식과 문장에서 해당 언어의 type 규칙에 따라 올바르게 사용되고 있는지를
검사하는 data type checking 수행, 그 결과를 syntax tree 혹은 symbol table에 저장
의미 분석기(semantic analyzer)가 수행
● 입력:
○ parsing으로 얻은 parse tree 또는 syntax tree
● 출력:
○ Semantic analysis가 이뤄진 parse tree 또는 syntax tree
○ Syntax directed translation을 이용하면 직접 intermediate code를 얻을 수도 있음
형 검사(type checking):
● 각 operator가 소스 프로그램 규칙에 의해 허용된 operand을 가졌는지 검사
● 예시) 어떤 언어에서 배열의 index는 int를 허용하는데 float이 사용되었다면 에러임을 지적
상수 정의(constant definition)
● 각 constant의 정의된 값을 symbol table에 보관하여 이후 적당한 기회에 기억 공간을 배정받고 초기값을 갖는다.
형 정의(type definition)
● 주어진 production rule의 의미에 의해 type의 자료 구조가 구성되며, 이는 기호표에 보관된다.
● Type definition에서 구성된 자료 구조는 형 설명자(type descriptor)를 만들어서 구성된 type에 대한
자료 구조 크기나 성격 등을 보관하고, 이후 type들이 메모리 공간을 배정받을 때 필요한 정보를 제공하게 한다.
변수의 형 선언(variable type declaration)
● 선언되는 변수들이 선언된 형에 의해 설명자를 얻을 수 있어 변수 이름과 형 설명자가 모두 같이 기호 표에
들어가며, 이때 각 변수는 기억 공간을 배정받아 해당 형을 구성하여 해당 변수에 기억 공간을 배정하게 된다.
수식 연산의 두 가지 종류:
● 형 고정 연산(type specific operation): Operand와 연산 결과의 type이 고정되어 있는 연산.
● 일반적 연산(generic operation): Operand와 연산 결과의 type이 변할 수 있는 연산.
예시) a + b와 같은 산술식에서, a와 b의 자료형이 각각 int형과 float형이라면 type specific operation에서는
에러이지만, generic operation에서는 a나 b의 type을 변환하여 연산.
Type conversion: 주어진 data type을 다른 type으로 변환
● 명시적 형 변환(explicit type conversion): 프로그래머가 명시적으로 type conversion을 요구
○ Explicit type conversion은 명령문으로 요구한 type conversion으로 cast operation이라고도 한 다.
● 묵시적 형 변환(implicit type conversion): 시스템에서 자동으로 type conversion
○ Implicit type conversion은 시스템에서 자동으로 형을 변환하는 것으로 자동 변환(automatic type
conversion) 또는 강제 형 변환(coercion)이라고 한다.
이는 컴파일러가 판단해서 결정하는 것이 아니라 언어 정의(language definition) 시간에 어떤 연산으로
할 것인지 결정해 놓는다.
Symbol table
Identifier (id) 에 대해 symbol table를 만든다.
● 첫째, id의 이름은 문자열로 나타낸다. 같은 이름이 여러 개의 블록이나 프로시저에서 사용된다면 이 id가
속해 있는 블록이나 프 로시저를 나타내는 표현이 있어야 한다.
● 둘째, id의 레벨, 형식 인자 formal parameter, 배열 등을 나타내준다.
● 셋째, 배열의 차원 수, 각 차원의 상한과 하한을 나타내야 한다.
● 넷째, 가능하다면 메모리에서 id의 위치를 나타내는 오프셋(offset) 등이 있어야 한다.
기호표는 특정 기호가 가진 속성을 포함하는 하나의 레코드로 구성되며, 전형적인 기호표는 다음과 같은 형태이다.

● Data type 칼럼은 type checking시 중요한 요소이며 코드 생성 시 메모리 할당공간을 제시함
● Symbol의 오프셋은 실행 시 id의 값을 얻기 위한 주소를 나타내며, 레벨은 블록 단계를 나타낸다
● 기타 속성은 코드 생성 혹은 에러 처리를 원활하게 하기 위한 줄 번호 관리 등을 포함
Semantic analysis 관점에서의 symbol table:
● symbol table에 수집된 attribute와 id의 사용이 타당한지 검사
● symbol을 검색하고 삽입하는 일이기 때문에 컴파일 시 많은 시간을 차지
● 효율적인 symbol table 구성은 컴파일 시간 단축에 있어 중요한 문제
● 메모리 제약이 있는 경우 symbol table의 크기도 줄여야 함
symbol table을 구성하는 세 가지 방법:
● 선형 리스트(linear list)
○ linear list는 구현이 간단하지만, n개의 item과 m개의 조회(inquiry)가 있을 때 자료의 수가 커지면
이를 모두 조사하여 접근하는 방법을 택하기 때문에 비효율적이다.
● 트리(tree)
○ 이진 탐색 트리(binary search tree) 방법은 구현하기가 어렵지만 (n+m)log n의 횟수가 소요되므로
n이 큰 경우에 효율적
● 해시표(hash table)
○ 해싱(hashing) 방법은 가장 효율적인 방식이다.
Symbol table based on Linear list
Linear list 에 새로운 id를 추가하려면
● 선형 리스트를 차례로 scan해야 하며,
● 새로운 식별자의 이름이 없는 경우에는 선형 리스트의 가장 끝에 새로운 식별자를 추가하고,
● 그에 대한 attribute를 기록한다.
장점: 최소한의 메모리를 사용
단점: n개의 id가 저장되어 있을 때 새로운 id를 삽입하려면 n개의 식별자를 scan한 다음에 삽입이 가능하므로
n이 크면 비효율적 따라서 선형 리스트 방법은 프로그램의 크기가 작은 작업의 컴파일에 사용됨.

Symbol table based on Tree structure
각 symbol table에 왼쪽과 오른쪽의 2개 링크 필드(link field)를 추가.
그리고 symbol를 만나는 순서에 의해 이진 검색 개념을 이용한 이진 탐색 트리를 구성한다.
새로 추가될 노드의 기호는 트리 각 노드의 id를 나타내는 이름과 비교하여, 새로 추가될 기호가
● 기존 노드의 이름보다 크면 그 노드의 오른쪽 링크 부분을 따라 다음 노드로 가고,
● 이름보다 작으면 왼쪽 링크 부분을 따라 다음 노드로 진행되는 과정을,
널(null) 링크를 만날 때까지 되풀이하고, 새로 정의된 기호가 들어 있는 노드를 연결한다.
장점: n개 id에 대하여 nlogn 의 시간이 필요하므로, n이 커질수록 linear list 대비 시간 측면에서 효율적
단점: 구현하기가 상대적으로 어려움

Symbol Table based on Hashing
방법은 새로 정의된 기호에 대해 해시 함수(hash function)를 적용하여 해시표서 그 위치를 찾아
삽입하는 방법이다.
이 구성표에 대한 검색은 삽입하는 방법과 같이 해시 함수를 적용하여 찾는다.
장점: 3가지 symbol table 구성 방법 중 가장 효율이 좋음
해시 함수로는 제산법(division method), 제곱값 중간법(mid-square method), 폴딩법 (folding method)
등이 사용된다.

Attribute Grammar
Attribute grammar: attribute, semantic rule을 사용하여 CFG를 확장
● 각각의 논터미널 기호 또는 터미널 기호의 attribute를 결합하여 semantic analysis에 이용
Attribute:
● 언어의 정의 시간, 번역 시간, 실행 시간까지 해당 특성이 결정 되는 시간에 따라 다양한 형태로 나타날 수 있다.
● 구하는 위치에 따라, Synthesized attribute와 Inherited attribute로 나뉨
● 예시) 변수의 자료형, 식의 값, 메모리에서 변수의 위치, 어떤 숫자의 유효 자릿수 등이다.
Synthesized attribute:
● Production rule의 lhs에 있는 논터미널 기호의 attribute가 production rule의 rhs에 있는 함수에 의해
결정되는 것을 말 한다.
● 즉 생성 규칙 X → ABC에 대해 다음과 같다: X.attribute ::= func(A.attribute, B.attribute, C.attribute).
Inherited attribute:
● Inherited attribute는 production rule의 lhs에 있는 논터미널 기호의 attribute를 이용하여
production rule의 rhs에 있는 논터미널 기호의 attribute가 결정되는 것을 말한다.
● 즉 생성 규칙 X → ABC에 대해 다음과 같다: A.attribute ::= func(X.attribute, B.attribute, C.attribute)
Terminologies:
● Binding: 속성을 확정하는 것.
Binding time: binding이 결정되는 시간
● Static binding: binding time이 프로그램 실행 이전인 경우
Dynamic binding: binding time이 프로그램 실행 중인 경우
Syntax-directed definition:
● CFG에 attribute과 semantic rule을 결합한 것 .
● Attribute는 grammar symbol과 결합하고, Semantic rule은 production rule과 결합
● 만약 X가 grammar symbol이고 a가 attribute라면 X.a는 특정 파스 트리 노드 X에서의 값 a를 나타냄
Semantic rule을 기술할 때에는:
● 논터미널 기호는 목적에 따라 문자열, 숫자, 자료형 등을 나타내기 위한 다양한 속성을 표현하고,
● 이런 속성을 점(.) 연산자를 이용하여 나타낸다.
● 예시) Nonterminal A의 attribute value를 나타내는 A.value와 메모리 공간을 나타내는 addr을
표현하기 위해 A.addr로 표기
각 노드에서 attribute value를 annotation으로 보여주는 annotated parse tree를 만들 수 있다.
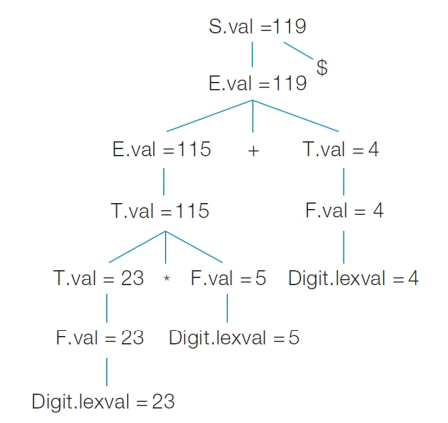
Example : 산술식 23 * 5 + 4$에 대한 annotated parse tree를 만들어보자

Example : 문장 real id1, id2, id3에 대한 annotated parse tree를 만들어보자


Type checking
Type checking:
● operator가 부적합한 operand에 적용되는지 검사 → 만약 발견되면 에러 발생
● Type checking을 수행하기 위해 컴파일러는
○ 소스 프로그램의 각 요소에 type expression을 부여한 후,
○ type expression이 어떤 논리 규칙의 집합에 부합하는지를 결정
○ 이 논리 규칙의 집합을 소스 프로그램의 type system이라고 부른다.
[정의] Type expression
● boolean, char, integer, real, void 등 elementary type은 type expression
● type name도 type expression
● type constructor도 type expression
● type expression을 value로 가질 수 있는 variable도 type expression
Data type
Elementary data type (기본자료형, 기본형):
● int, real등과 같이 언어에서 미리 정의된 type
● boolean, char와 같이 구현하기 쉬운 특성을 가짐.
● 그 값이 내부적으로 명시적인 구조가 아니라는 점에서 simple type 이라고도 한다.
새로운 자료형을 정의할 수도 있음.
● 예시) sub-range type, enumeration type.
● 배열, 레코드, 구조체(structure)와 같은 type constructor를 이용
○ Type constructor: 존재하는 type을 parameter로 받아 정의되는 새로운 구조의 형을 반환하는 함수.
○ Array type constructor는 index type과 component type을 parameter로 받아 새로운 array type을 생성
○ Record or structure type constructor는 이름과 type list를 받아 새로운 type을 생성
Pointer type:
● 다른 type의 value를 가리키는 값으로 이루어져 있음
● Pointer type value: 기본이 되는 type의 value가 저장된 메모리 위치의 주소
Type system
Type system:
● Type expression을 프로그램의 여러 부분에 할당하는 규칙의 모임
● Type checker는 이러한 type system을 구현한 것.
Static check: 컴파일러 단에서 수행하는 검사
● Type check
● Flow of control check: 제어를 이동시키는 흐름을 검사
● Uniqueness check: 어떤 객체가 정확히 한 번만 정의되었는지 검사
● Name related check: 같은 이름이 두번 이상 나타났는지 검사
Note:
Sound type system: type error를 런타임에 dynamic하게 검사하지 않아도 되는 type system을 말한다.
만약 프로그램이 type error 없이 실행된다는 것을 컴파일러가 보장할 수 있다면 이 언어의 구현은
strongly typed이라고 한다.
Type conversion
Type specific operation:
● operand에 따라 연산 결과의 type이 고정되어 있는 연산
● 파스칼 언어에서는 형 고정 연산을 허용하므로 피연산자의 형이 다르면 바로 에러 메시지를 내보낸다.
Generic operation:
● operand에 따라 연산 결과의 type이 변할 수 있는 연산
● C 언어에서는 generic operation을 허용한다.
○ 수식 x + i (x는 real, i는 int) 에 대해서, 정수 연산과 실수 연산에는 서로 다른 기계 명령어가
사용되기 때문에 바로 계산할 수는 없음.
○ 컴파일러는 +의 피연산자 중 하나를 변환하여 덧셈의 operand이 동일한 type이 되도록 한다.
Type conversion 규칙은 언어마다 다양하다.
● 자바의 규칙은 정보를 보존하는 확장(widening) 변환과 정보를 잃을 수 있는 축소 (narrowing) 변환을 구별한다. ● 확장 변환 규칙에서는 계층이 더 낮은 type 더 높은 type 확장될 수 있다.
따라서 char는 int 또는 float로 확장될 수 있지만 short로는 확장될 수 없음.
그리고 축소 변환 규칙에서는 char, short, byte가 각각 서로에 대해 축소 변환이 가능하다.
Implicit conversion:
● 하나의 형에서 다른 형으로의 변환을 컴파일러가 자동적으로 수행
● 강제 형 변환(coercion)이라고도 하며 많은 언어의 확장 변환에서만 허용한다.
Explicit conversion:
● 형 변환을 하기 위해 프로그래머가 명백히 서술하는 경우.
캐스트(cast)라고도 한다.
Example : ni = ba * po - 60 + ni / (abc + 50); 에서 ni, ba, po는 실수형, abc는 정수형일 때,
type checking을 하고, annotated parse tree를 그려보자.
가정: Generic operation을 허용하는 언어이며, 정수형과 실수형의 연산은 정수형을 실수형으로
변환하여 실수형 결과를 출력

'학교에서 들은거 정리 > 기초컴파일러구성' 카테고리의 다른 글
| Structural data type, Runtime Environment (0) | 2021.11.26 |
|---|---|
| Intermediate Code Generation (0) | 2021.11.25 |
| LALR Parsing (0) | 2021.11.12 |
| CLR Parse / LALR Parse (0) | 2021.11.05 |
| SLR Parsing / CLR Parser (0) | 2021.11.04 |



