
mojo's Blog
System-Level I/O 본문
Unix I/O
※ Unix I/O Overview
Linux 파일은 m 바이트의 sequence 이다.
- B0, B1, ..., Bk, ..., Bm-1
Cool fact : 모든 I/O 디바이스는 파일로 표시된다.
- /dev/sda2 (/usr disk partition)
- /dev/tty2 (terminal)
커널도 파일로 표시된다.
- /boot/vmlinuz-3.13.0-55-generic (kernel image)
- /proc (kernel data structures)
file 은 chunk 들의 단위이다.
이때 chunk 는 block 으로 "512 byte" 로 구성되어 있으며 read, write 에 대한 unit 이다.
디바이스에 파일을 mapping 하여 Unix I/O 라 불리는 간단한 인터페이스를 커널에서 export 할 수 있다.
파일 열기 및 닫기 : open() 및 close()
파일 읽기 및 쓰기 : read() 및 write()
현재 파일 위치 변경(seek)
- 읽거나 쓸 파일에 대한 다음 오프셋을 나타냅니다.
- lseek()

※ File Types
각 파일에는 시스템에서의 역할을 나타내는 유형이 있다.
- Regular file : arbitrary 한 데이터를 포함한다.
- Directory : 파일들의 관련된 그룹의 인덱스이다.
- Socket : 다른 기계상의 프로세스와 통신하기 위한 용도이다. (동일한 기계상에서도 가능)
위 유형을 제외한 기타 파일 형식들
- Named pipes (FIFO)
- Symbolic links (ex : 바로가기)
- character and block devices
※ Regular Files
Regular file 에 arbitrary 한 데이터가 포함되어 있다.
응용 프로그램에서 텍스트 파일과 바이너리 파일을 구별하는 경우가 많다.
- 텍스트 파일은 ASCII(1 byte) 또는 Unicode(2 byte) 문자만 포함하는 일반 파일이다.
- 바이너리 파일 그 외 모든 것 (ex : 객체 파일, JPEG 이미지)
- 커널은 신기하게도 ASCII, Unicode 에 대한 차이점을 인식하지 못한다.
텍스트 파일은 text lines 의 시퀀스입니다.
- text lines 은 줄 바꿈 문자로 끝나는 문자 시퀀스이다('\n').
- Newline 은 0xa로 ASCII 줄바꿈 문자(LF)와 동일하다.
다른 시스템의 End of line(EOL) indicators
- Linux 및 Mac OS : '\n' (0xa)
- line feed(LF)
- Windows 및 인터넷 프로토콜 : '\r\n' (0xd 0xa)
- Carriage return(CR) 을 한 다음에 Line feed(LF)

※ Directories
디렉토리는 링크 배열로 구성된다.
- 각 링크는 파일 이름을 파일에 매핑한다.
각 디렉토리에는 적어도 2개 이상의 엔트리가 있다.
- . 는 현재 디렉토리에 대한 링크이다.
- .. 는 현재 디렉토리의 부모 디렉토리에 대한 링크이다.
디렉토리를 조작하기 위한 명령어
- mkdir : 빈 디렉토리를 만듭니다.
- ls : 디렉토리 내용 표시
- rmdir : 빈 디렉토리 삭제
usr 디렉토리로 이동 하고 workspace 디렉토리로 이동하면 a.txt, b.txt, c.txt, d.txt 가 있다고 가정해보자.
디렉토리는 링크 배열로 구성되어 있으며 각 링크는 파일 이름을 파일에 매핑한다고 하는데 아래와 같은 상황이라고 볼 수 있다.

※ Directory Hierarchy
모든 파일들은 /(slash)라는 이름의 root 디렉터리에 의해 고정된 계층으로 구성된다.

커널은 각 프로세스의 현재 작업 디렉토리(cwd)를 유지하며 cd 명령어를 사용하여 변경될 수 있다.
※ Pathnames
pathnames 으로 표시되는 계층 내에 파일들의 위치를 2가지로 구분할 수 있다.
- Absolute pathname : '/'로 시작하고 루트로부터의 경로를 나타낸다.
- /home/droh/hello.c
- Relative pathname : 현재 작업 디렉토리의 경로를 나타낸다.
- ../home/droh/hello.c

※ Opening Files
파일을 열면 해당 파일에 액세스할 준비가 되었음을 커널에 알린다.
아래 코드와 같이 현재 위치에서 etc 디렉토리에 hosts 파일을 읽기모드로 open 할 수 있다.
int fd; /* file descriptor */
if ((fd = open("/etc/hosts", O_RDONLY)) < 0) {
perror("open");
exit(1);
}
작은 식별 정수로 file descriptor 를 반환한다.
- fd == - 1 : 오류가 발생했음을 나타낸다.
Linux 쉘에 의해 작성된 각 프로세스는 터미널과 관련된 3개의 open 파일로 시작된다.
- 0: 표준 입력(stdin)
- 1: 표준 출력(stdout)
- 2: 표준 오류(stderr)
0, 1, 2 은 고정되어 있으며, 예를 들어 "foo" 라는 파일을 open 한다고 할 때 얻을 수 있는 file descriptor 는 3 이다.
즉, 0, 1, 2 그 다음 숫자인 3 이 리턴된다.
※ Closing Files
파일을 닫으면 해당 파일에 대한 액세스가 완료되었음을 커널에 알린다.
아래 코드와 같이 파일을 닫을 수 있다.
int fd;
int retval;
if ((retval = close(fd)) < 0) {
perror("close");
exit(1);
}
이미 닫힌 파일을 닫으면 스레드화된 프로그램에서 장애가 발생할 수 있다.
Moral : close()와 같은 정상적인 함수의 경우에도 항상 리턴 코드를 체크해야 한다.
※ Reading Files
파일을 읽으면 현재 파일 위치에서 메모리로 지정한 바이트만큼 복사되고 파일 위치가 업데이트 된다.
버퍼 사이즈만큼 파일을 읽어들이는 코드는 다음과 같다.
char buf[512];
int fd; /* file descriptor */
int nbytes; /* number of bytes read */
/* Open file fd ... */
/* Then read up to 512 bytes from file fd */
if ((nbytes = read(fd, buf, sizeof(buf))) < 0) {
perror("read");
exit(1);
}
파일 fd 으로부터 buf 에 읽어들인 바이트 수를 반환한다.
- return type : ssize_t 으로 부호가 있는 정수
- nbytes < 0 : 오류가 발생했음을 나타탬
- short count(0 ≤ nbytes < sizeof (buf)) : 가능하지만 오류는 아니다.
예를 들어서 위 코드에서 fd 가 가르키고 있는 해당 파일이 2000 byte 라고 가정해보자.
그리고 buf size 만큼 파일을 더 이상 읽지 못할때까지 읽는다고 해보자.
① 512 byte => buf 에다가 512 byte 만큼 완전하게 read 했다.
② 1024 byte => buf 에다가 512 byte 만큼 완전하게 read 했다.
③ 1536 byte => buf 에다가 512 byte 만큼 완전하게 read 했다.
④ 2000 byte => buf 에다가 464 byte 만큼 불완전하게 read 했다. (short count 발생!)
short counts 가 발생할 경우 그 다음에 해당하는 파일을 read 할 수 없는 상태가 되버린다.
※ Writing Files
파일 쓰기는 메모리에서 현재 파일 위치로 바이트를 복사한 후 현재 파일 위치를 업데이트 한다.
write 코드는 다음과 같다.
char buf[512];
int fd; /* file descriptor */
int nbytes; /* number of bytes read */
/* Open the file fd ... */
/* Then write up to 512 bytes from buf to file fd */
if ((nbytes = write(fd, buf, sizeof(buf)) < 0) {
perror("write");
exit(1);
}
fd 에서 buf 파일에 쓴 바이트 수를 반환한다.
- nbytes < 0 : 오류가 발생했음을 나타낸다.
- read 와 마찬가지로 short counts 는 가능하지만 에러가 아니다.
※ Simple Unix I/O example
stdin 을 통해 input 을 받아들이고 stdout 을 통해 output 을 내면서 1 byte 마다 실행하는 코드를 살펴보도록 하자.
#include "csapp.h"
int main(void)
{
char c;
while(Read(STDIN_FILENO, &c, 1) != 0)
Write(STDOUT_FILENO, &c, 1);
exit(0);
}
위 코드는 아주 정상적인 코드이다.
그러나 1 byte 씩 읽고 쓰는 이러한 코드는 correctness 관점에서 ok 이지만, efficiency 관점에서 no 이다.
read(), write() 를 호출하면 system call 인 _read(), _write() 가 호출이 된다.
즉, user level 에서 read(), write() 를 호출하면 system call 을 호출하게 되며 자연스럽게 kernel 측에서 _read(), _write() 가 호출되는데 이 과정에서 context switch 가 발생하게 된다.
"context switch" 가 발생하는데 clock cycle 이 대략 1,000,000 정도 된다고 한다.
즉, 한 싸이클이 1 ns 라고 할 경우 1,000,000 ns = 1 ms 으로 read(), write() 을 호출하는데 드는 비용이 적어도 2 ms 을 넘어서는 것을 짐작할 수 있다.
사용자가 단순히 타이핑을 적절하게 한다고 하면 상관은 없겠지만, 굉장히 많은 양의 타이핑을 할 경우에 context switch 를 하면서 한 문자를 read 하고 write 하는데 드는 overhead 가 상당할 것으로 짐작이 된다.
따라서 이러한 cost 를 줄이기 위해서 이전에 봤던 코드처럼 char buf[512] 와 같이 설정하여 sizeof(buf) 만큼 읽어들여서 쓰고를 반복하는 것이 efficiency 관점에서 좀 더 ok 하다고 볼 수 있다.
※ On Short Counts
다음과 같은 상황에서 short counts 가 발생할 수 있다.
- 읽기 시 (파일 끝) EOF 발생
- 터미널에서 text line 읽기 ('\n', '\r\n')
- 네트워크 소켓 읽기 및 쓰기
다음과 같은 상황에서는 short counts가 발생하지 않는다.
- 디스크 파일에서 읽기(EOF 제외)
- 디스크 파일에 쓰기
가장 좋은 방법은 항상 short counts 를 고려하는 것이다.
RIO (robust I/O) package
※ The RIO Package
RIO는 Short counts 의 대상이 되는 네트워크 프로그램과 같은 애플리케이션에서 효율적이고 견고한 I/O 를 제공하는 wrapper 들의 세트이다.
RIO는 두 가지 다른 기능을 제공한다.
- 바이너리 데이터의 버퍼링되지 않은 입출력
- rio_readn, rio_writen
- 텍스트 라인 및 이진 데이터의 버퍼링된 입력
- rio_readlineb, rio_readnb
- 버퍼링된 RIO 루틴은 thread-safe 이며 동일한 descriptor 에서 임의로 interleave 된다.
※ Unffered RIO Input and Output
Unix read and write와 동일한 인터페이스이다.
네트워크 소켓 상의 데이터 전송에 특히 유용하다.
#include "csapp.h"
ssize_t rio_readn(int fd, void *usrbuf, size_t n);
ssize_t rio_writen(int fd, void *usrbuf, size_t n);
Return: num. bytes transferred if OK, 0 on EOF (rio_readnonly), -1 on error
rio_readn : EOF가 발생한 경우에만 short counts 를 반환한다. (읽을 바이트 수를 알고 있는 경우에만 사용)
rio_writen : short counts 를 반환하지 않는다.
rio_readn, rio_writen 에 대한 호출은 동일한 descriptor 에서 임의로 interleave 될 수 있다.
※ Implementation of rio_readn
ssize_t rio_readn(int fd, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nread;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nread = read(fd, bufp, nleft)) < 0) {
if (errno == EINTR) /* interrupted by sig handler return */
nread = 0; /* and call read() again */
else
return -1; /* errno set by read() */
}
else if (nread == 0)
break; /* EOF */
nleft -= nread;
bufp += nread;
}
return (n - nleft); /* return >= 0 */
}
- nread < 0 : read 가 비정상적으로 실행된 경우
- errno == EINTR : signal handler 가 호출된 경우 nread 를 0으로 해서 다시 read 를 호출할 수 있도록 한다.
- errno != EINTR : -1 을 반환하게 된다.
- nread == 0 : EOF 즉, File 의 끝 부분까지 도달한 경우 멈춘다.
- nread > 0 : 정상적으로 파일을 read 한 경우이다.
※ Buffered RIO Input Functions
내부 메모리 버퍼에 부분적으로 캐시된 파일에서 text line 과 binary data 를 효율적으로 읽는다.
#include "csapp.h"
void rio_readinitb(rio_t *rp, int fd);
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen);
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n);
Return: num. bytes read if OK, 0 on EOF, -1 on error
rio_readlineb : fd 에서 maxlen bytes 의 text line 을 읽고 usrbuf 에 읽어들인 line 을 저장한다.
네트워크 소켓에서 text line 을 읽을 때 특히 유용하다.
정지 조건은 아래와 같다.
- maxLen bytes 만큼 읽기
- EOF 발생
- 줄바꿈('\n')이 발생한 경우 (readlineb 이니깐 줄바꿈이 생기면 정지하는게 당연)
rio_readnb : 파일에서 n bytes 까지 읽는다.
정지 조건은 아래와 같다.
(이 함수는 line 을 읽는게 아닌 텍스트 전체를 읽는거이므로 줄바꿈이 발생할 경우 정지하지 않음)
- maxLen bytes 만큼 읽기
- EOF 발생
rio_readlineb, rio_readnb 에 대한 호출은 동일한 descriptor 로 임의로 interleave 될 수 있다.
- warning : rio_readn 호출은 interleave 되지 않음 (버퍼링되지 않은 경우)
※ Buffered I/O : Implementation
파일에서 읽기용
파일에서 읽었지만 사용자 코드로 아직 읽지 않은 바이트를 보관하기 위한 버퍼가 파일에 있다.
rio_t 라는 구조체에 다음과 같은 정보가 들어있다.

typedef struct {
int rio_fd; /* descriptor for this internal buf */
int rio_cnt; /* unread bytes in internal buf */
char *rio_bufptr; /* next unread byte in internal buf */
char rio_buf[RIO_BUFSIZE]; /* internal buffer */
} rio_t;
rio_cnt : 내부 버퍼에서 읽지 못한 bytes 이다.
rio_bufptr : 내부 버퍼에서 읽지 못한 부분의 첫 시작 부분을 point 한다.
rio_buf : 내부 버퍼이다.
※ RIO Example
인풋을 MAXLINE 만큼 읽어들인 후에 저장되어 있는 buf 를 읽어들인 수 만큼 화면에 출력하도록 하는 코드를 간단하게 보도록 하자.
#include "csapp.h"
int main(int argc, char **argv)
{
int n;
rio_t rio;
char buf[MAXLINE];
Rio_readinitb(&rio, STDIN_FILENO);
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0)
Rio_writen(STDOUT_FILENO, buf, n);
/* $end cpfile */
exit(0);
/* $begin cpfile */
}
/* $end cpfile */

이전에 봤었던 문자 하나씩 읽고 쓰는 코드보다 더 효율적이다.
system call 을 부르는데 드는 시간이 \(\frac{1}{MAXLINE}\) 배 만큼 감소됨으로써 효율적이게 되었다.
Metadata, sharing, and redirection
※ File Metadata
Metadata : 데이터에 대한 데이터이며, 이러한 경우를 파일 데이터라고 한다.
커널에 의해 유지되는 파일별 메타데이터로 stat 및 fstat 함수를 사용하여 유저들에 의해 액세스된다.
아래는 stat 이라는 구조체로 파일에 대한 정보들을 담는 여러 변수들이 선언되어 있다.
/* Metadata returned by the stat and fstat functions */
struct stat {
dev_t st_dev; /* Device */
ino_t st_ino; /* inode */
mode_t st_mode; /* Protection and file type */
nlink_t st_nlink; /* Number of hard links */
uid_t st_uid; /* User ID of owner */
gid_t st_gid; /* Group ID of owner */
dev_t st_rdev; /* Device type (if inode device) */
off_t st_size; /* Total size, in bytes */
unsigned long st_blksize; /* Blocksize for filesystem I/O */
unsigned long st_blocks; /* Number of blocks allocated */
time_t st_atime; /* Time of last access */
time_t st_mtime; /* Time of last modification */
time_t st_ctime; /* Time of last change */
};
※ Example of Accessing File Metadata
argv[1] 에 해당하는 이름이 파일인지, 디렉토리인지, 그 외인지를 판단하며 읽기 접근 권한이 있는지를 판단하는 간단한 코드를 살펴보도록 하자.
#include "csapp.h"
int main (int argc, char **argv)
{
struct stat stat;
char *type, *readok;
/* $end statcheck */
if (argc != 2) {
fprintf(stderr, "usage: %s <filename>\n", argv[0]);
exit(0);
}
/* $begin statcheck */
Stat(argv[1], &stat);
if (S_ISREG(stat.st_mode)) /* Determine file type */
type = "regular";
else if (S_ISDIR(stat.st_mode))
type = "directory";
else
type = "other";
if ((stat.st_mode & S_IRUSR)) /* Check read access */
readok = "yes";
else
readok = "no";
printf("type: %s, read: %s\n", type, readok);
exit(0);
}

./a.out .. : ".." 은 현재 디렉토리의 부모 디렉토리를 나타내며 읽기 권한이 허용된다.
./a.out statcheck.c : "statcheck.c" 는 파일이며 읽기 권한이 허용된다.
이때, chmod 000 statcheck.c 를 하여 user, group, 그리고 others 모드에 모든 권한을 비허용할 경우 다시 실행한다면 읽기 권한이 허용되지 않는다고 출력된다.
directory 인지 file 인지에 대한 정보, user, group, others 에 대한 읽기, 쓰기, 실행 권한을 10 bit 으로 표현할 수 있다.

※ How the Unix Kernel Represents Open Files
2개의 fd 는 서로 다른 2개의 open file 을 참조한다.
fd = 1(stdout)은 terminal 을 가리키고 fd = 4는 디스크 파일을 연다.

※ File Sharing
두 개의 서로 다른 file table entry 들을 통해 동일한 디스크 파일을 공유하는 두 개의 서로 다른 fd 가 있다.
예를 들어, 같은 filename 을 사용하여 open 을 두 번 호출할 수 있다. (fd1 = open("foo", ...), fd2 = open("foo", ...))
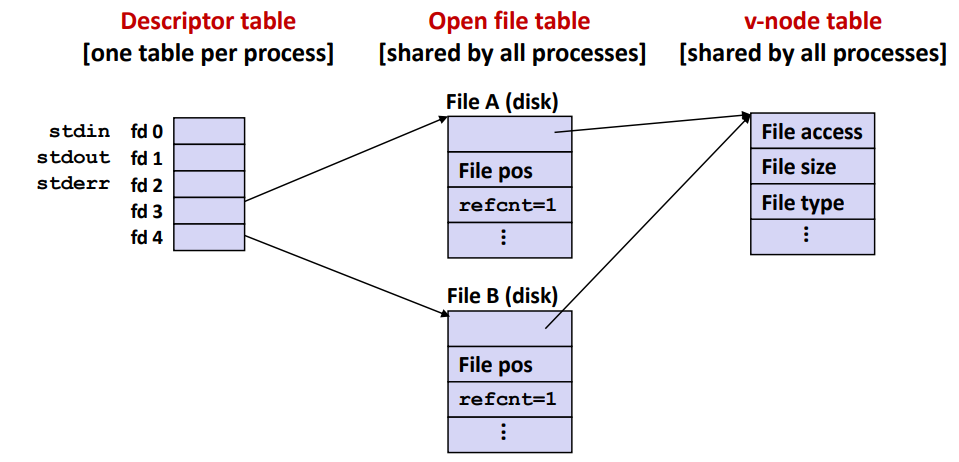
그렇다면 파일 data 를 어디서 읽어오는 걸까?
v-node table 에서 실제 파일 data 를 읽을 수 있도록 하는 pointer 가 존재한다고 한다.
아래 사진을 보도록 하자.

대략 이런식으로 v-node table 으로 point 하고 그 다음에 SSD 에 실제 파일 내용을 point 하는 무언가가 존재한다고 한다.
즉, fd 값을 통해 open file table 를 point 하고 v-node table 을 point 하고 그 다음에 SSD 에 실제 파일 내용을 point 하는 것으로 이해하면 좋을거 같다.
※ How Processes Share Files : fork
자식 프로세스는 부모 프로세스의 open file 들을 상속받는다.
fork 를 띄우기 전과 띄운 후의 사진을 보도록 하자.


open file table 에서 refcnt 는 reference count 를 의미한다.
즉, Descriptor 에서 reference 가 몇 번 일어났는지에 대한 value 를 의미하는데 fork 를 함으로써 부모 프로세스의 open file 들을 상속받아서 refcnt 값이 증가하게 된 것을 확인할 수 있다.
※ I/O Redirection
다음과 같은 I/O redirection 을 보도록 하자.
linux> ls > foo.txt
위와 같은 redirection 을 구현하기 위해 어떻게 구현해야 할까?
정답은 dup2(oldfd, newfd) 함수를 이용하는 것이다.
dup2(oldfd, newfd) 는 newfd 가 point 하고 있는 open file table 을 oldfd 가 point 하고 있는 open file table 과 동일하게 변하게 된다.
아래와 같이 변하는 것으로 볼 수 있다.

좀 더 구체적으로 open file table, v-node table 가 어떻게 point 되는지 확인해보도록 하자.


dup2(4, 1) 을 호출함으로써 fd = 1 가 stdout 에 대한 open file table 을 fd = 4 가 가르키고 있는 open file table 으로 point 하는 것으로 변하게 된 걸 알 수 있다.
그리고 v-node table 에 대한 point 변화는 없는 것을 알 수 있다.
Standard I/O
※ Standard I/O Functions
C 표준 라이브러리(libc.so)에는 상위 수준의 standard I/O 기능이 포함되어 있다.
Examples of standard I/O functions :
- 파일 열기 및 닫기(fopen, fclose)
- 바이트 읽기 및 쓰기(fread, fwrite)
- 텍스트 라인 읽기 및 쓰기(fgets, fputs)
- 포맷된 읽기 및 쓰기(fscanf, fprintf)
※ Standard I/O Streams
Standard I/O 모델에서는 파일을 streams 으로 연다.
- 메모리 내의 file descriptor 및 buffer 에 대한 추상화이다.
C 프로그램은 3 개의 open streams 으로 시작한다. (stdio.h 에 정의됨)
- stdin (표준 입력)
- stdout (표준 출력)
- stderr (표준 오류)
#include <stdio.h>
extern FILE *stdin; /* standard input (descriptor 0) */
extern FILE *stdout; /* standard output (descriptor 1) */
extern FILE *stderr; /* standard error (descriptor 2) */
int main() {
fprintf(stdout, "Hello, world\n");
}
※ Buffered I/O : Motivation
Applications 은 한 번에 한 문자씩 읽고 쓰는 경우가 많다
- getc, putc, ungetc
- gets, fgets
- 텍스트 줄을 한 번에 한 글자씩 읽는다. 즉, 줄 바꿈에서 멈춘다.
Unix I/O 로 구현하면 비용이 많이 든다
- read and write 함수는 Unix kernel 호출이 필요하다.
- 10,000 을 넘어선 clock cycle 발생
Solution : Buffered read
- Unix read 를 사용하여 바이트 블록을 가져온다.
- User input 함수들은 버퍼에서 한 번에 1바이트씩 가져옵니다.
- 비어 있을 때 버퍼를 다시 채움

※ Buffering in Standard I/O
Standard I/O 함수들은 버퍼링된 I/O 를 사용한다.
다음과 같이 printf 가 진행되는 과정을 살펴보도록 하자.

fflush(stdout) 를 실행하게 된다면?
표준 출력 버퍼를 비우라는 의미이다.
즉, 버퍼에 저장된 내용을 출력하면 된다.
위 예제에서 각 문자를 buf 에 담다가 newLine 을 만나게 되면 "hello\n" 가 최종적으로 버퍼에 저장되며 fflush(stdout) 을 호출하게 되면 write(1, buf, 6) 을 호출하게 됨으로써 화면에 출력이 이루어진다.
Closing remarks
※ Unix I/O vs. Standard I/O vs. RIO

Standard I/O, RIO 는 low-level 인 Unix I/O 를 사용함으로써 구현되는 것은 이전에서 확인했다.
그렇다면 셋 중에 어떤게 더 효율적일까?
각각 장단점을 살펴보도록 하자.
※ Pros and Cons of Unix I/O
장점
- Unix I/O는 I/O 의 가장 일반적인 형태로 가장 낮은 overhead 형식이다.
- 기타 모든 I/O 패키지는 Unix I/O 기능을 사용하여 구현된다.
- UNIX I/O는 file metadata 에 액세스하기 위한 기능을 제공한다.
- Unix I/O 함수는 async-signal-safe 하며 signal handlers 에서 안전하게 사용할 수 있다.
단점
- short counts 를 처리하는 것은 까다롭고 오류가 발생하기 쉽다.
- 텍스트 줄을 효율적으로 읽으려면 버퍼링이 필요하지만 까다롭고 오류가 발생하기 쉽다.
- 이 두 가지 문제는 모두 Standard I/O 및 RIO 패키지로 해결된다.
※ Pros and Cons of Standard I/O
장점:
- 버퍼링을 통해 읽기 및 쓰기 시스템 호출 수를 줄임으로써 효율성을 향상시킨다.
- Short counts 는 자동으로 처리된다.
단점:
- file metadata 에 접근하기 위한 기능을 제공하지 않는다. (low-level 단에서 해결가능)
- Standard I/O 기능은 async-signal-safe 하지 않으며 signal handlers 에 적합하지 않다.
- Standard I/O 는 네트워크 소켓의 입출력에는 적합하지 않다.
- 소켓의 제한과 상호 작용하지 않는 스트림에 대한 제한은 제대로 문서화되어 있지 않다.
'학교에서 들은거 정리 > 시스템프로그래밍' 카테고리의 다른 글
| Concurrent Programming (0) | 2022.04.14 |
|---|---|
| Network Programming: Part II (0) | 2022.04.08 |
| Network Programming: Part I (0) | 2022.04.01 |
| Exceptional Control Flow: Signals and Nonlocal Jumps (0) | 2022.03.25 |
| Exceptional Control Flow: Exceptions and Process (0) | 2022.03.17 |



