
mojo's Blog
File system Implementation 본문
What on-disk structures to represent files and directories?
- Contiguous, Extents, Linked, FAT, Indexed, Multi-level indexed
- Which are good for different metrics?
What disk operations are needed for:
- make directory, open file, write/read file, close file
on-disk structures : disk 상에 있는 구조체로 file, directory를 나타내기 위한 용도다.
contiguous, extents, linked, fat, indexed, multi-level indexed 등의 방법이 있다.
그에 대한 장단점에 대해 알아보도록 하자.
Part 1 : Disk Structure

파일시스템 입장에서 보면 block들의 배열이다.
위 사진과 같이 64개의 block이 존재하며 각 block마다 크기는 sector size의 배수라고 보면 된다.
sector size = 512 byte 라면 multiple sectors : 2, 4, 8, ...
block = sector size * ( )
ex : block size가 4 Kb 라면 ( ) = 8 이 된다. (즉, 8개의 sector 존재)
보통 block size를 4Kb 라고 본다고 한다.
64 * Block size = 256 kb (HDD or SDD)
Persistence store : 데이터가 사라지지 않는 영속성을 가짐
Similarity to Memory?

실제 physical address 로 변환하기 위해서 각 프로세스 마다 Page table 이 존재했다.
64개의 블럭을 어떤 file이 어떤 block을 갖는지 이러한 mapping 만 있으면 찾아갈 수 있다.
=> 파일시스템이 해야할 일
아래와 같이 각 file 별로 block을 갖고 있으며 해당 block을 추적하여 읽는 구조이다.
Contiguous Allocation
Allocate each file to contiguous sectors on disk
- Meta-data: Starting block and size of file
- OS allocates by finding sufficient free space
=> Must predict future size of file; Should space be reserved?
- Example: IBM OS/360
A, B, C 라는 파일이 연속으로 할당될 때 어떻게 할당되는가?
=> Meta-data가 필수로 필요하다. (파일의 블럭이 어디에 존재하는지에 대한 정보)
결국 Starting block, size에 대한 정보를 알면 된다. (Meta -data)

ex : 위 사진에서 A 부터 10이라고 가정해보자
A : (10, 3), B : (14, 4), C : (18, 3) <= 이게 Meta-data 임
Internal fragmentation 은 block 내에서 sector 전부를 쓰지 않고 일부를 사용하는 경우이며
External fragmentation 은 여러개의 block에서 contiguous하게 할당 x 할때를 의미한다.
위 방식으로는 external fragmentation 문제가 존재한다. (non-internal)
ex : 위 사진에서 이전, 이후가 block이 전부 채워졌다고 가정할 때 D라는 파일을 할당하려고 할 때 6개의 블럭이
필요하다고 가정하자.
이 경우 contiguous 한 영역이 없기 때문에(최대 4만 가능) 생성 불가능하다. (공간이 있음에도 불구하고)
즉 이러한 문제를 external fragmentation 이다.
따라서 위 문제를 해결하기 위해 주기적인 compaction 이 필요하다.
그러나 주기적으로 공간을 마련하기 위해 block들을 움직여야 하는데 이로 인한 overhead로 성능 저하가 발생한다.
하지만 장점은 굉장히 구현이 간단하다는 점이다.
그러나 파일 append 가 가능하지 않음
ex : 위 사진으로 연속 4개의 block을 할당한 file B 에서 하나의 block 을 첨가하려는 경우 채울 수 없음.
(A나 C는 가능하겠지만?)
Sequential accesses : Excellent performance
random access : 간단하게 계산을 함으로써 위치 찾기가 가능하다.
meta-data를 위한 space : 다른 방법에 비해서 좋다. 그리고 meta-data 에 대한 overhead가 적음
Small number of Extents

파일 당 Extent를 가져서 contiguous 한 region 을 여러개 할당하는 방법이다.
Meta-data : Small array (2 - 6) designating each extent
Each entry : starting block and size
이때 extent 끼리는 contiguous 하지 않는다. (contiguous 할 수는 있음)
external fragmentation 경감이 가능하다. (그러나 여전히 존재할 수 있음)
extent가 있다고 할 경우 grow 가능하다. (extent가 있을 때까지만 grow 가능)
extent 끼리 seeking 해야 하므로 여전히 성능이 좋다.
Linked Allocation

Allocate linked-list of fixed-sized blocks (multiple sectors)
Meta-data: Location of first block of file, Each block also contains pointer to next block.
Examples: TOPS-10, Alto
만약 Block size를 512 Byte 라고 할 때 ptr 처리를 위한 size 4 Byte 가 추가된다면?
=> Block + ptr = 512 + 4 = 516 Byte, size가 늘어난다. (ptr가 추가되지만 size 유지 불가)
이로 인한 space 낭비가 일어나게 된다.
즉, 위 설명으로 External fragmentation 제거가 가능하지만 internal fragmentation 이 존재하는 것을 알 수 있다.
그리고 layout 에 따라 성능이 달라짐 block 마다 pointer를 가져야 하므로 공간 낭비가 존재한다.

File-Allocation Table (FAT File System)

Variation of Linked allocation
Keep linked-list information for all files in on-disk FAT table
Meta-data: Location of first block of file
And, FAT table itself
FAT table 안에 A : {7,8,9}, ... 와 같은 정보가 들어간다.
그러나 table 을 참조할 때 약간의 overhead가 존재할 수 있다.
즉, FAT table을 항상 매번 읽어야 하는 단점이 존재한다.
모든 데이터를 읽을때마다 두개의 disk location 으로부터 읽어야 한다.
entry가 많아지면 메모리에 캐싱하기 위한 메모리가 비싸기 때문에 캐싱이 안될 수 있다.
즉, 일부만 캐싱해야하는데 얼마만큼 caching 할건지에 대한 Issue가 존재한다.
Indexed Allocation
지금까지 여러 시행착오를 거치면서 incremental 하게 improve 를 해왔다.
그러나 최적화가 되기는 하지만 그만큼 complex 하다는 점이 존재한다.
Allocate fixed-sized blocks for each file
- Meta-data : Fixed-sized array of block pointers.
- Allocate space for ptrs at file creation time
FAT allocation이랑 다르게 (집합으로 표시한 table)
indexed allocation 은 파일마다 array 를 갖고 있는데 array 에는 block pointer를 갖고 있다.
ex : A는 어떤걸 갖고 B는 어떤걸 갖고 C는 ...
표현을 하게 되면 A : {12, 13, 14} 이거 하나를 array로 있다. (FAT table 과 동일해보임)
문제점은 파일 마다 meta-data를 갖고 있다는 점이다. (안쓰는 Null 부분에 대한 waste 가 존재함)
array를 잡을 때 이에 대한 크기를 어떻게 잡을 것인가?
정적으로 할당하는 점에서 얼마만큼의 파일 크기를 받아올 때 매우 적은 사이즈를 받아오는 점에서
굉장히 공간 효율성을 저하시키는 문제점이 존재하는 것으로 보인다. (동적으로 이를 해결한다면?)
결국 trade-off 가 존재하는 것은 어쩔 수 없는 것 같다.

Multi-Level Indexing
Variation of Indexed Allocation
- Dynamically allocate hierarchy of pointers to blocks as needed
- Meta-data: Small number of pointers allocated statically
Additional pointers to blocks of pointers
- Examples: UNIX FFS-based file systems, ext2, ext3
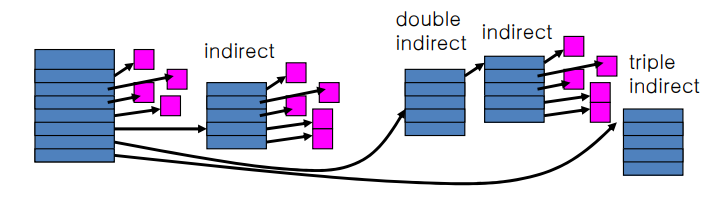
리눅스 계열의 파일 시스템임
chunk를 갖고 directing 하는 addressing 이 존재하며 핑크색으로 된 것은 direct 주소가 들어간다.
공간 낭비, 파일 제한 등을 해결할 수 있다.
그러나 문제점은 파일이 엄청 큰 경우(1 Gb file 라고 가정) 만약 뒷부분을 랜덤으로 접근한다고
한다면 indirection 을 여러번 해야하는 문제가 발생한다. (double로 가거나 triple 로 가거나 ...)
마치 해당 link를 계속해서 쫓아가기 때문에 이로 인한 overhead 발생으로 성능이 좋지는 않다.
(Indexed allocation 보다는 좋음)
결국 Tree structure 를 갖는 것을 알 수 있겠다.
On-Disk Strucures
1. data block
2. inode table
3. indirect block
4. directories
5. data bitmap
6. inode bitmap
7. superblock
FS Structs : Empty Disk
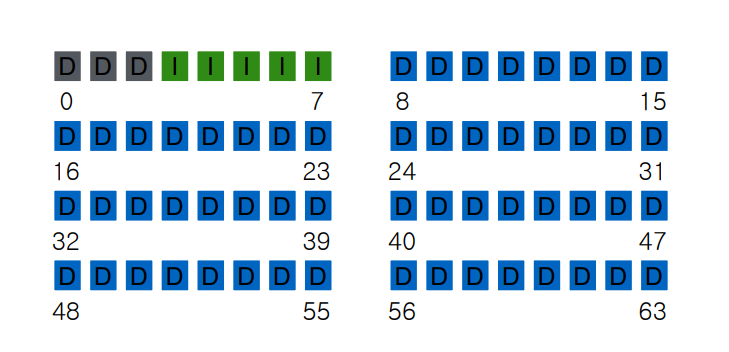
2가지 partition으로 나눠서 구성된다 => D로 적힌게 Data Blocks
일부는 data block 이 아닌 meta block 으로 나뉘며 대부분 data block 으로 구성된다.
그리고 나머지 중에 일부를 Inode 라고 부른다.
Inode 는 file 에 대한 meta-data 인데 Disk block 의 size를 만약 4 Kb 라고 한다면
전체 크기는 256 Kb 가 됨 => 64 * 4 = 256 Kb 으로 Disk capacity 으로 불린다.
Data Block 에 대한 영역은 4 * 56 = 224 Kb 만 사용하는 것이다.
위에서 언급한 것을 통해 Inode 도 4 Kb 임을 알 수 있다.
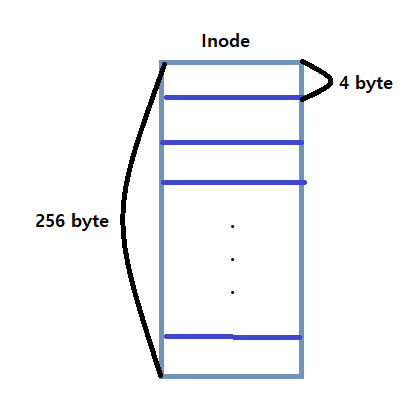
Inode에 대한 meta-data 의 size는 보통 256 Byte 라고 한다.
One Inode Block
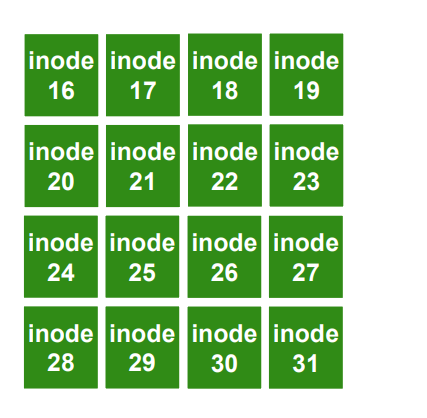
Each inode is typically 256 bytes (depends on the FS, maybe 128 bytes)
4KB disk block
16 inodes per inode block
하나의 inode 블럭 내부에 16개의 inode들이 들어간다.
앞쪽에는 Inode block이 5개 존재하는데 Inode block 안에 16개의 inode가 존재하므로
5 * 16 = 80 즉, 80개의 inode가 존재하며 Disk 구조에서 만들 수 있는 파일 갯수를 의미한다.
Inode

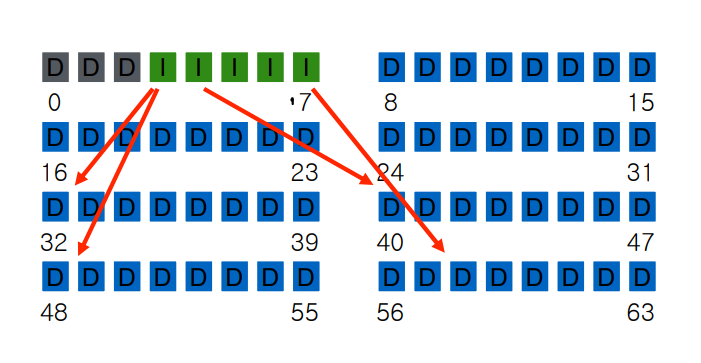
Inode는 실제로 포인터를 갖고 있기 때문에 실제 데이터가 어딨는지를 알 수 있다.
Assume single level (just pointer s to data blocks)
What is max file size?
Assume 256-byte inodes (all can be used for pointers) and 4-byte addrs.
How to get larger files?
inode 256 byte 에 addrs 4 byte 로 나누게 되면 64 이다.
즉, 64 * Data Block size(4Kb) = 256Kb 가 결국 max file size 이다.
Disk Capacity이 4 * 64 = 256kb 이며 usuable disk capacity 는 4 * 56 = 224 kb 가 나온다.
근데 usuable disk Capacity가 224kb 이므로 256kb 까지 만들 수 없다.
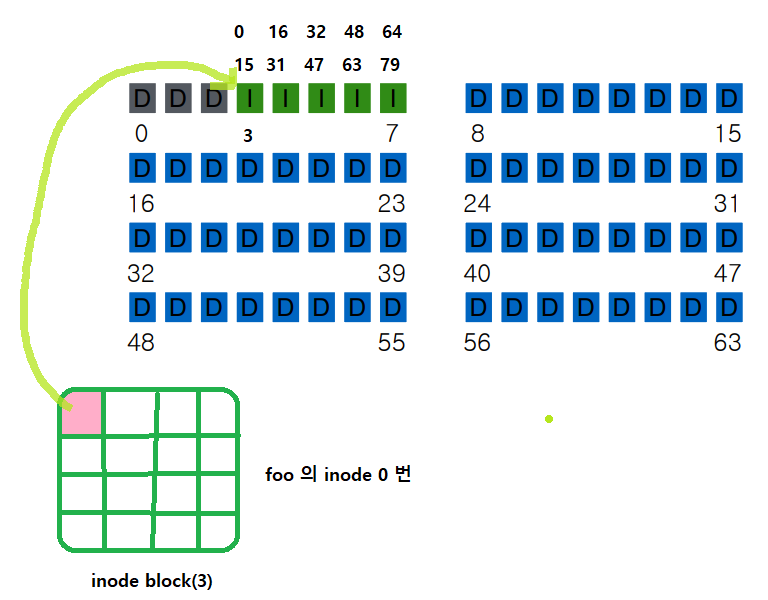
좀더 큰 파일을 만들기 위해서 indirection 방법이 도입된다.
만약 indirect 를 하게 된다면 파일 사이즈가 커지는 overhead 가 존재
즉 Multi-level indexing 구조를 통해서 아래와 같이 해주면 굉장히 효율적이며
큰 파일도 생성이 가능하게 된다.

파일 시스템은 inode number 를 통해서 유니크한 번호를 할당하는데 0부터 79가 할당된다. (inode 번호)
각각에 대해서 단순히 계산하면 바로 위치를 알 수 있게 된다.
=> 고정되어 있기 때문!
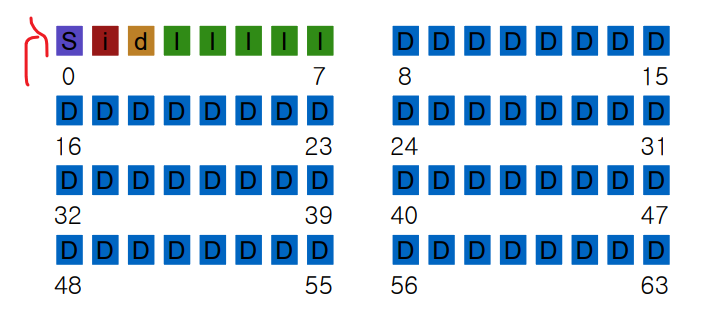
그렇다면 아직 살펴보지 못한 3개의 block은 어떤 역할을 하는지 살펴보도록 한다.
data block 중에 어떤게 사용되고 사용 안되는지에 대한 checking 그리고 이러한 정보들을 어떻게 담을까?
=> Bitmaps 방법을 사용한다. (첫번째 inode bitmap, 두번째 data bitmap)

superblock
Need to know basic FS configuration metadata, like:
- block size
- # of inodes
- Start location of inode table
- etc
File system 맨앞에 있으며 block size, inode 갯수 inode table의 시작 주소 등에 대한 정보를 기억한다.
Data block이 56개 inode 5개 block size 4kb ... 이러한 정보를 0번째 block 에서 갖는다는 뜻이다.
만약 0 번째 Sector가 깨지면 Disk를 읽을 수 없음 (가장 중요한 정보를 잃어버렸으니...?)

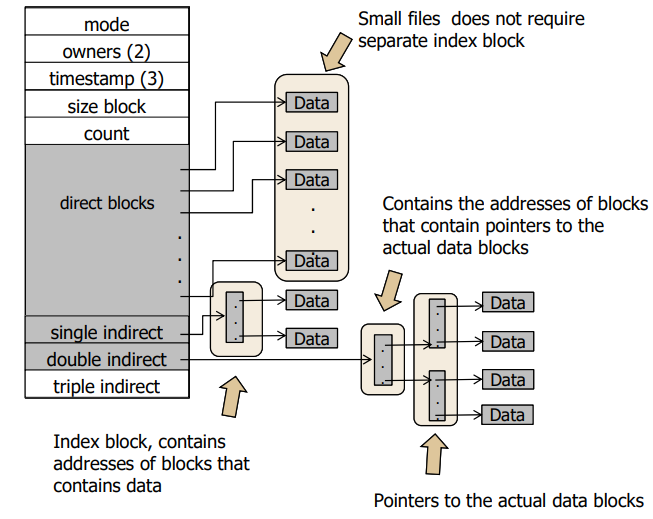
색깔이 칠해진건 32번째 inode 번째를 사용한다는 것을 의미한다.
0번부터 79가 할당되고 32번을 읽어보면 오른쪽 사진에 있는것을 확인할 수 있다.
direct block은 data block에 대한 주소값을 갖고, indirect 주소 또한 갖고 있다.
파일시스템이 비트맵을 읽고 비트맵을 가지고 8번부터 63번까지 free인지 아닌지를 알 수 있다.
small file들은 대부분 direct 되고 large block은 direct되거나 여러번 indirect 를 거친다.
file의 offset이 앞부분이면 direct block에 대한 point 가 가능하지만,
file의 offset이 뒷부분이면 indirect block 까지 가야 해서 여러 블럭을 읽기 때문에 그에 대한
주소를 알 수 있는데 그로 인한 Disk access를 해야 한다. (뒤로갈수록 느려질수 밖에 없음 - Tree traversal)
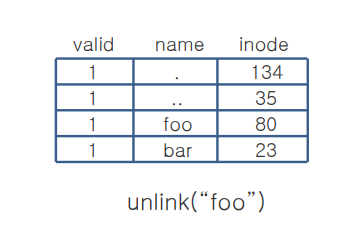
Directory
디렉토리 엔트리가 테이블 형식으로 나타내는 것을 확인할 수 있다. (.은 자신 / ..부모 디렉)

VSFS, EXT4
VSFS : 파일 이름이 적혀있고 inode 번호(5, 2, 12), record 길이가 (4, .. 8), string length(2, 3, 4,...) 널을 포함한다.
EXT4 : 각각의 inode 적히고 파일 타입(2 번이 디렉, 1번이 파일) 파일 네임의 길이, 레코드 길이가 적혀 있다.
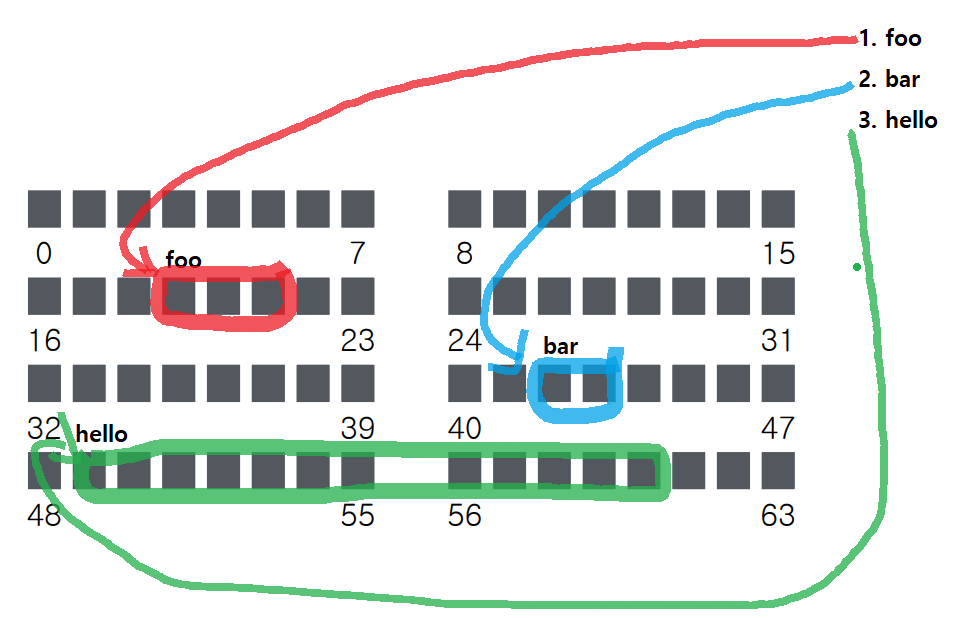
Create
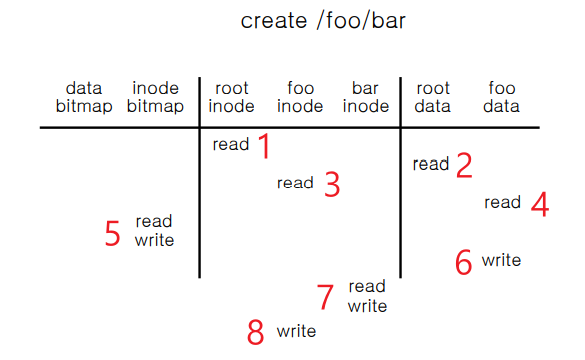
1. root inode를 read 해야한다. (foo 라는 디렉토리에 entry 추가해야함, "bar" 파일을 create 하려면)
2. root data를 read 하면 하위 디렉토리를 전부 read 가 가능하며 그 중에 foo를 알 수 있다.
3. foo의 inode 번호를 보고나서 그걸 read 한다.
4. 그리고 foo의 data를 read 한다.
create 하고자 하는 파일이 있는지 없는지 보기 위해 디렉토리 엔트리를 찾는다.
foo data block을 read 하는데 없는 경우 "bar" 라는 파일 create 해도 되는걸 알 수 있다.
5. inode bitmap 으로 번호 할당을 해야한다.
따라서 inode bitmap 을 read하고 write 를 해줘야 한다.
6. 따라서 foo directory 에 "bar"라는 파일 이름이 생성되므로 해당 엔트리를 추가해야한다.
foo data에 write 해준다.
7. 그리고 bar inode 를 read 하고 write 한다.
8. 마지막으로 foo inode 에 write는 생성된 시간을 작성해줘야 한다.
8단계를 걸쳐서 "bar" 파일을 만드는 과정이다.
파일을 create 할 때 disk가 여러번의 read, write를 해야하므로 너무 느린것을 알 수 있다.
그래서 일부는 캐싱을 이용하여 read, write를 줄여 속도를 높이는 방법이 있다고 한다.
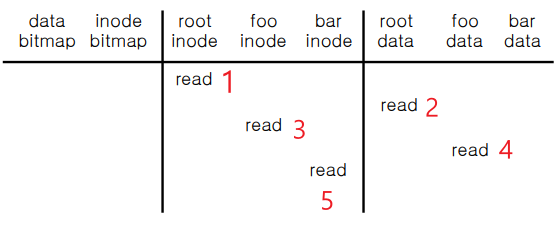
Open

먼저 파일 Open을 위해 목표는 "bar" file의 inode 번호를 읽는 것이다.
차례대로 root 파일 부터 시작해서 inode, metadata를 읽어야한다. (root부터 순서대로)
1. root inode 를 read 한다.
2. root data 를 read 하면 하위 디렉토리 및 파일을 전부 read 가 가능하며 그 중에 foo를 알 수 있다.
3. foo inode 를 read 한다.
4. foo data 를 read 하면 하위 디렉토리 및 파일을 전부 read 가 가능하며 그 중에 bar를 알 수 있다.
5. bar의 inode read 한다.
Write
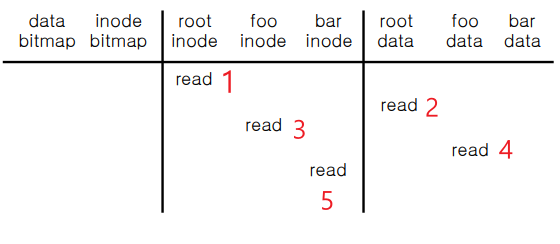

Open의 연장선이다.
Open에서 bar 파일의 inode를 read 하기까지를 완료하였으므로 write 하는 과정을 살펴본다.
6. data bitmap을 read 하고 write 한다.
7. bar data에 해당하는 block에 write 한다.
8. 그 후에 bar inode 번호에 write(update) 한다.
Read
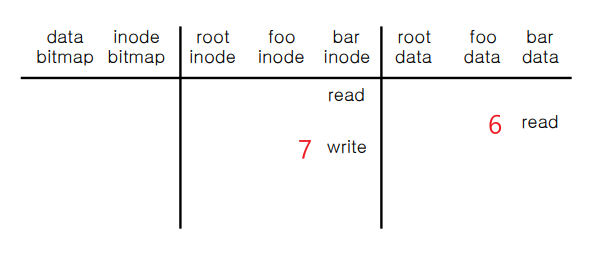
write와 동일하게도 Open의 연장선이다.
Open에서 bar 파일의 inode를 read 하기까지를 완료하였으므로 이번엔 read 하는 과정을 살펴본다.
6. bar data에 해당하는 block을 read 한다.
7. 그 후에 bar inode 번호에 write(update) 한다.
Close

아무것도 할게없다. (해당하는 File descriptor table 에서 제거함)
Efficiency
위에서 과정을 살펴봤듯이 read, write 에 대한 buffering 이 존재한다.
따라서 이러한 buffering을 다루기 위해서 Cache 를 이용해야 한다.
Write Buffering
Why does procrastination help?
- Overwrites, deletes, scheduling
- 공유 구조체(예: 비트맵+dirs)는 종종 overwrite 된다. (오랫동안 버퍼링할 경우)
- 버퍼링할 양, 버퍼링할 기간 등을 결정합니다.
- 즉, trade-off 연구를 잘해서 이를 효율적으로 해결해야 한다.
Caching and Buffering
Reading and writing can very IO intensive.
- File open: two IO for each directory component and one read for the data.
Buffer Cache
- cache the disk blocks to reduce the IO.
- LRU replacement
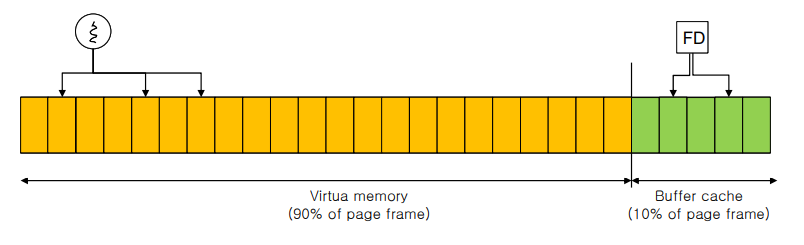
- Static partitioning: 10% of DRAM, inefficient usage

Page Cache
- Merge virtual memory and buffer cache
- A physical page frame can host either a page in the process address space or a file block.
- Process uses page table to map a virtual page to a page frame.
- A file IO uses “address_space”(Linux) to map a file block to a physical page frame.
- Dynamic partitioning
'학교에서 들은거 정리 > 운영체제' 카테고리의 다른 글
| Files and Directories (0) | 2021.11.27 |
|---|---|
| Hard Disk Drives (0) | 2021.11.24 |
| Semaphore and Common Concurrency Problem (0) | 2021.11.18 |
| Conditional Variables (0) | 2021.11.12 |
| Lock based Data Structure (0) | 2021.11.11 |



