
mojo's Blog
Lock based Data Structure 본문
Evaluating Spin Locks
이전에 구현했었던 TestAndSet 함수에 대해서 생각해보도록 한다.
1. Correctness : critical section에 들어가는 issue를 해결하였음 => Ok
2. Fairness : 정확하게 1 : 1 비율로 lock이 걸린다는 보장이 없음
또한, thread spinning이 영원히 spin 할지도 모름 => No
3. Performance : spinning을 통한 지속적인 CPU 점유 발생 즉, overhead 발생
Compare-And-Swap (SPARC)
주소(ptr)에 대한 값이 expected값과 동일한지에 대한 Test를 진행하도록 하는 매커니즘이다.
(1) 만약 동일한 경우 : 주소(ptr) 값에 new 값을 업데이트 하고 이전 주소(ptr)값을 반환한다.
(2) 동일하지 않은 경우 : 업데이트 없이 actual 값(*ptr)을 반환한다.
int CompareAndSwap(int *ptr, int expected, int new){
int actual = *ptr;
if(actual == expected)
*ptr = new;
return actual;
}
...
void lock(lock_t *lock){
while(CompareAndSwap(&lock->flag, 0, 1) == 1)
; // spin...
}
위와 같이 CompareAndSwap 함수를 이용하여 lock함수를 구현할 수 있다.
Load-Linked and Store-Conditional (MIPS)
Load-Linked, Store-conditional 에 대한 코드를 보도록 한다.
int LoadLinked(int *ptr){
return *ptr;
}
int StoreConditional(int *ptr, int value){
if(no one has updated *ptr since the LoadLinked to this address){
*ptr = value;
return 1;
} else{
return 0;
}
}
...
void lock(lock_t *lock){
while(1){
while(LoadLinked(&lock->flag) == 1)
; // spin until it's zero
if(StoreConditional(&lock->flag, 1) == 1)
return;
}
}
주소에 intermittent 하게 저장되지 않은 경우에만 store-conditional이 충족된다.
(1) success : value 값을 *ptr 값에 할당하고 1을 return 한다.
(2) fail : 어떠한 업데이트 없이 0을 return 한다.
lock 함수를 위 코드보다 더 concise 하게 작성한 경우는 다음과 같다.
void lock(lock_t *lock){
while(LoadLinked(&lock->flag)||!StoreConditional(&lock->flag, 1))
; // spin
}
Fetch-And-Add
Atomically increment a value while returning the old value at a particular address.
이 함수는 Hardware atomic instruction 임을 알아두자.
int FetchAndAdd(int *ptr){
int old = *ptr;
*ptr = old + 1;
return old;
}
Ticket Lock(Advanced)
Ticket Lock이란 fetch-and-add 함수를 통해서 만들어진다.
여기서 중요한 점은 Ticket Lock을 구현함으로써 fairness가 드디어 보장이 된다.
구현 코드는 다음과 같다.
typedef struct __lock_t {
int ticket;
int turn;
} lock_t;
void lock_init(lock_t *lock){
lock->ticket = lock->turn = 0;
}
void lock(lock_t *lock) {
int myturn = FetchAndAdd(&lock->ticket);
while(lock->turn != myturn)
; // spin
}
void unlock(lock_t *lock) {
FetchAndAdd(&lock->turn);
}
lock의 turn이 myturn이랑 같지 않으면 spin, 같으면 critical section 으로 들어가는 구조임을 알 수 있다.
그러나 문제는 여전히 CPU의 유효한 cycle을 낭비하는 문제를 가지고 있다.
So Much Spinning
Hardware 기반으로 구현된 lock은 simple 하다.
하지만 이러한 해결책들이 과연 효율적인지에 대한 의문이 들 수 있다.
여태까지 본 lock 구현에 대해서는 spinning에 대한 해결을 하지 못했다는 점이다.
Any time a thread gets caught spinning, it wastes an entire time slice doing nothing but checking a value.
즉, loop문을 돌 때 time slice 전부를 가지고 돌기 때문에 이로 인한 overhead가 큰 문제가 있다.
이를 해결하기 위해 OS Support가 필요하다.
A Simple Approach: Just Yield
Spin이 돌 때 CPU를 포기하여 다른 thread에게 CPU 권한을 주는 방법이다.
즉, running state 에서 ready state 로 변환하면서 ready queue 에 넣도록 OS system이 support 해야 한다.
그러나 context switch로 인한 비용이 상당하며 starvation에 대한 문제가 여전히 존재한다는 점이 있다.
void init() {
flag = 0;
}
void lock() {
while(TestAndSet(&flag, 1) == 1)
yield();
}
void unlock() {
flag = 0;
}
Lock-based Concurrent Data structure
Adding locks to a data structure makes the structure thread safe.
Concurrent Counters without Locks
typedef struct __counter_t {
int value;
} counter_t;
void init(counter_t *c) {
c->value = 0;
}
void increment(counter_t *c) {
c->value++;
}
void decrement(counter_t *c) {
c->value--;
}
int get(counter_t *c) {
return c->value;
}
간단하지만 scalable 하지 않다는 점이 있다.
Concurrent Counters with Locks
typedef struct __counter_t {
int value;
pthread_lock_t lock;
} counter_t;
void init(counter_t *c) {
c->value = 0;
pthread_mutex_init(&c->lock, NULL);
}
void increment(counter_t *c) {
pthread_mutex_lock(&c->lock);
c->value++; // critical section!
pthread_mutex_unlock(&c->lock);
}
void decrement(counter_t *c) {
pthread_mutex_lock(&c->lock);
c->value--;
pthread_mutex_unlock(&c->lock);
}
int get(counter_t *c) {
pthread_mutex_lock(&c->lock);
int rc = c->value;
pthread_mutex_unlock(&c->lock);
return rc;
}
structure 에다가 single lock을 첨가하였다.
data structure을 manipulate 하도록 하는 routine을 호출할 때 lock을 획득할 수 있는 것을 알 수 있다.
The performance costs of the simple approach
각 쓰레드는 공유된 단일 counter를 업데이트 한다.
이때 각 쓰레드는 counter를 1,000,000 번 update 한다.
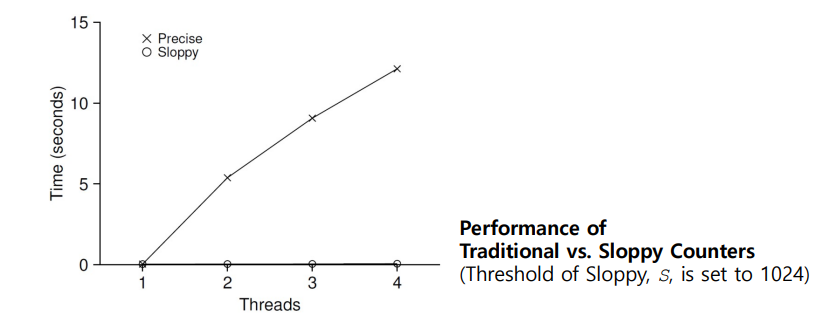
쓰레드 갯수가 증가하면서 value를 업데이트하거나 lock을 풀때 전체적으로 쓰레드의 critical section
에 대한 처리가 많아질 것이다.
만약 쓰레드가 4개라면 counter는 총 4,000,000 번 update 하게 된다.
즉, 이러한 update가 증가함으로써 쓰레드의 갯수가 증가할 때마다 결국 critical section에 대한
접근이 증가하고, 또 race condition을 생각해보면 이러한 operation을 manipulate할 때 lock을 획득하지 못한
쓰레드들이 lock wait을 하는것 까지 고려하면 결국 Time이 증가할 수 밖에 없다.
=> Synchronized counter scales poorly.
그래서 Sloopy Counters 를 이용하여 위 사진과 같이 거의 0에 가까운 Time에 쓰레드를 돌릴 수 있다.
Sloppy counter
The sloppy counter works by representing ...
(1) A single logical counter via numerous local physical counters, on per CPU core
(2) A single global counter
(3) There are locks : One for each local counter and one for global counter
예를 들어서 CPU가 4개 있다고 해보자.
그러면 4개의 local counter, 그리고 1개의 global counter가 존재한다.
When a thread running on a core wishes to increment the counter.
- It increment its local counter.
- Each CPU has its own local counter:
(1) Threads across CPUs can update local counters without contention.
(2) Thus counter updates are scalable.
- The local values are periodically transferred to the global counter.
(1) Acquire the global lock
(2) Increment it by the local counter's value
(3) The local counter is then reset to zero.
local counter, global counter에 대한 정리가 필요하다.
각 CPU 별로 local counter를 소유하고 있다.
local counter의 값은 thread 별로 어떠한 개입없이 update 되는데 이로 인해 counter update가
scalable 하다는 것을 알 수 있다.
그리고 local 값들이 주기적으로 global counter으로 전달이 되는데
(1) 전달받는 순간 global lock을 획득하고
(2) local counter 값으로 인해 global counter 값이 증가하게 된다.
(3) 그로 인해 local counter 값이 0으로 reset 되며 이러한 과정이 반복되는 것을 알 수 있다.
How often the local-to-global transfer occurs is determined by a threshold, S (sloppiness).
- The smaller S: The more the counter behaves like the non-scalable counter.
- The bigger S: The more scalable the counter.
The further off the global value might be from the actual count.
S가 커질수록 scalable 이 보장되는 것을 알 수 있다.
그러나 어디든지 trade-off가 있기 마련...
실제로 count와 global 값이 약간의 차이가 있을 수 있다는 점이다.
Sloppy counter example
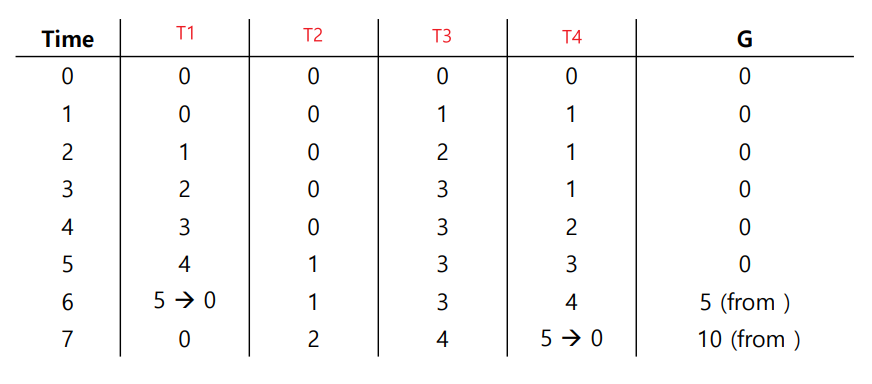
Sloppy Counter에 대한 Tracing 을 살펴보도록 하자.
먼저 threshold S값은 5로 세팅되었다.
그리고 각 쓰레드(T1, T2, T3, T4)는 각 CPU 4개를 점유하고 있으며, 각 쓰레드가 local counters
(L1, L2, L3, L4) 를 업데이트 하는 과정을 볼 수 있다.
(1) Time = 6 일 때, T1의 local counter(L1)이 threshold 값에 도달하였으므로 이로인해
global lock을 획득함과 동시에 global counter 값이 threshold 값 만큼 증가하고 T1의
local counter(L1)이 0으로 reset 된다. (global counter = 5)
(2) Time = 7 일 때 T4의 local counter(L4)이 threshold 값에 도달하였으므로 이로인해
global lock을 획득함과 동시에 global counter 값이 threshold 값 만큼 증가하고 T4의
local counter(L4)이 0으로 reset 된다. (global counter = 10)
Importance of the threshold value S
Each of four threads increments a counter 1 million times on four CPUs.
- Low S -> Performance is poor, The global count is always quite accurate.
- High S -> Performance is excellent, The global count lags.

Time과 Sloppiness는 반비례하다.
즉, trade off는 분명하며 Performance, global count 둘중 하나는 포기해야 하는 일이 발생한다.
Sloppy Counter Implementation
const int NUMCPUS = the number of CPUs
typedef struct __counter_t {
int global; // global count
pthread_mutex_t glock; // global lock
int local[NUMCPUS]; // local count (per cpu)
pthread_mutex_t llock[NUMCPUS]; // ... and locks
int threshold; // update frequency
} counter_t;
// init: record threshold, init locks, init values
// of all local counts and global count
void init(counter_t *c, int threshold) {
c->threshold = threshold;
c->global = 0;
pthread_mutex_init(&c->glock, NULL);
int i;
for (i = 0; i < NUMCPUS; i++) {
c->local[i] = 0;
pthread_mutex_init(&c->llock[i], NULL);
}
}
// update: usually, just grab local lock and update local amount
// once local count has risen by ’threshold’, grab global
// lock and transfer local values to it
void update(counter_t *c, int threadID, int amt) {
pthread_mutex_lock(&c->llock[threadID]);
c->local[threadID] += amt; // assumes amt > 0
if (c->local[threadID] >= c->threshold) { // transfer to global
pthread_mutex_lock(&c->glock);
c->global += c->local[threadID];
pthread_mutex_unlock(&c->glock);
c->local[threadID] = 0;
}
pthread_mutex_unlock(&c->llock[threadID]);
}
// get: just return global amount (which may not be perfect)
int get(counter_t *c) {
pthread_mutex_lock(&c->glock);
int val = c->global;
pthread_mutex_unlock(&c->glock);
return val; // only approximate!
}
Concurrent Linked Lists
// basic node structure
typedef struct __node_t {
int key;
struct __node_t *next;
} node_t;
// basic list structure (one used per list)
typedef struct __list_t {
node_t *head;
pthread_mutex_t lock;
} list_t;
void List_Init(list_t *L) {
L->head = NULL;
pthread_mutex_init(&L->lock, NULL);
}
int List_Insert(list_t *L, int key) {
pthread_mutex_lock(&L->lock);
node_t *new = malloc(sizeof(node_t));
if (new == NULL) {
perror("malloc");
pthread_mutex_unlock(&L->lock);
return -1; // fail
}
new->key = key;
new->next = L->head;
L->head = new;
pthread_mutex_unlock(&L->lock);
return 0; // success
}
int List_Lookup(list_t *L, int key) {
pthread_mutex_lock(&L->lock);
node_t *curr = L->head;
while (curr) {
if (curr->key == key) {
pthread_mutex_unlock(&L->lock);
return 0; // success
}
curr = curr->next;
}
pthread_mutex_unlock(&L->lock);
return -1; // failure
}
Single Linked List 으로 구현하였으며 lock, unlock을 정확하게 호출해야 한다.
특히, 예외 처리는 반드시 필요하다.
실패할 경우에 unlock은 반드시 해줘야 하고 안해줄 경우 error가 발생하게 된다.
List_Lookup 함수는 node를 하나하나 살펴보면서 해당 node의 key 값이 parameter로 받은 key 값과
동일할 경우 unlock을 하고 0을 return 한다.
그렇지 않은 경우 unlock을 하고 -1을 return 한다.
위 경우는 lock과 unlock을 함수의 시작부분과 함수 끝부분에 호출을 한다.
즉, critical section 영역이 넓어져서 이로 인한 concurrency 문제를 일으킬 수 있다.
따라서 critical section 영역을 좁히도록 lock, unlock의 호출을 어디에다가 배치할 것인지에
대해서는 중요한 issue 중 하나이다.
Concurrent Linked List: Rewritten
void List_Init(list_t *L) {
L->head = NULL;
pthread_mutex_init(&L->lock, NULL);
}
void List_Insert(list_t *L, int key) {
// synchronization not needed
node_t *new = malloc(sizeof(node_t));
if (new == NULL) {
perror("malloc");
return;
}
new->key = key;
// just lock critical section
pthread_mutex_lock(&L->lock);
new->next = L->head;
L->head = new;
pthread_mutex_unlock(&L->lock);
}
int List_Lookup(list_t *L, int key) {
int rv = -1;
pthread_mutex_lock(&L->lock);
node_t *curr = L->head;
while (curr) {
if (curr->key == key) {
rv = 0;
break;
}
curr = curr->next;
}
pthread_mutex_unlock(&L->lock);
return rv; // now both success and failure
}
위와 같이 수정함으로써 concurrency를 높일 수 있다.
Scaling Linked List
Hand-over-hand locking (lock coupling)
- Add a lock per node of the list instead of having a single lock for the entire list.
- When traversing the list,
(1) First grabs the next node's lock.
(2) And then releases the current node's lock.
- Enable a high degree of concurrency in list operations.
=> However, in practice, the overheads of acquiring and releasing locks for each node
of a list traversal is prohibitive.
이번에는 node 각각을 lock을 잡는 기법으로 Scaling Linked List 라고 부른다.
이로 인한 문제점은 무엇일까?
각각의 node에 대한 lock을 획득하고 놓을 때의 overhead 가 상당하다는 점이 있다.
Michael and Scott Concurrent Queues
There are two locks.
- One of the head of the queue.
- One for the tail.
- The goal of these two locks is to enable concurrency of enqueue and dequeue operations.
Add a dummy node
- Allocated in the queue initialization code
- Enable the separation of head and tail operations
Queue의 head 부분, tail 부분에 대한 lock 처리를 함으로써 concurrency를 높이는 기법이다.
dummy node를 추가함으로써 head, tail 에 대한 operation을 분리하고 initialization code에서
Queue 에 대한 할당이 일어난다.
typedef struct __node_t {
int value;
struct __node_t *next;
} node_t;
typedef struct __queue_t {
node_t *head;
node_t *tail;
pthread_mutex_t headLock;
pthread_mutex_t tailLock;
} queue_t;
void Queue_Init(queue_t *q) {
node_t *tmp = malloc(sizeof(node_t));
tmp->next = NULL;
q->head = q->tail = tmp;
pthread_mutex_init(&q->headLock, NULL);
pthread_mutex_init(&q->tailLock, NULL);
}
void Queue_Enqueue(queue_t *q, int value) {
node_t *tmp = malloc(sizeof(node_t));
assert(tmp != NULL);
tmp->value = value;
tmp->next = NULL;
pthread_mutex_lock(&q->tailLock);
q->tail->next = tmp;
q->tail = tmp;
pthread_mutex_unlock(&q->tailLock);
}
int Queue_Dequeue(queue_t *q, int *value) {
pthread_mutex_lock(&q->headLock);
node_t *tmp = q->head;
node_t *newHead = tmp->next;
if (newHead == NULL) {
pthread_mutex_unlock(&q->headLock);
return -1; // queue was empty
}
*value = newHead->value;
q->head = newHead;
pthread_mutex_unlock(&q->headLock);
free(tmp);
return 0;
}
(1) Queue_Init() 에 대한 경우는 다음과 같다.
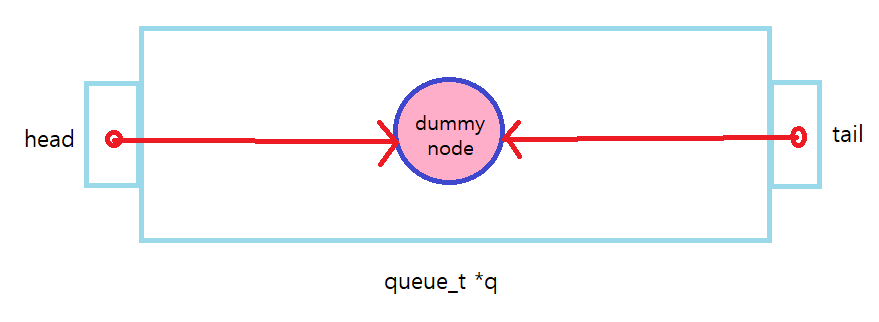
dummy node를 malloc 하여 얻고 queue의 head, tail부분이 dummy node를 point 하도록 한다.
(2) Queue_Enqueue()
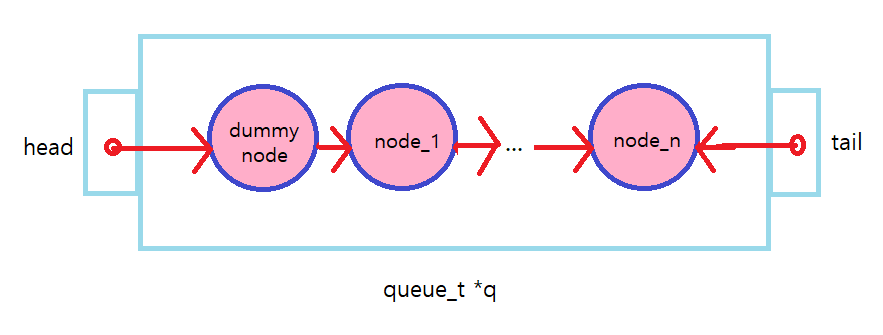
tail의 끝 node에 계속해서 새로운 node를 insert하는 작업이 이뤄진다.
그리고 lock과 unlock은 Queue가 insert 즉, node를 point 하는 과정에서 일어난다.
따라서 node를 point 하는 과정은 critical section 이므로 해당 영역을 lock하고 unlock 해줘야 한다.
(3) Queue_Dequeue()
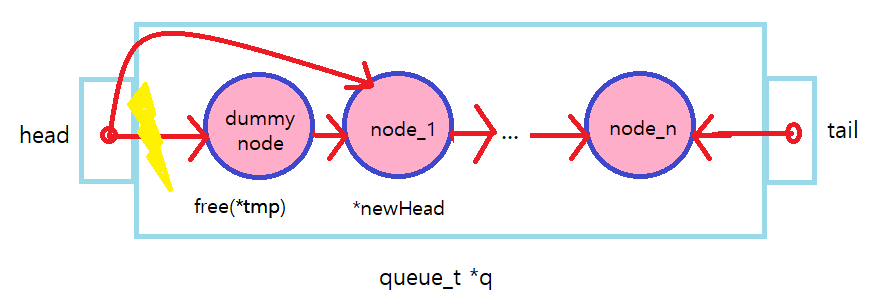
*newHead의 값을 *value에 할당하고 head를 가리키고 있는 node를 free 시킨다.
그러나 Queue에 node가 하나만 있을 경우(*newHead 없는 상태) Queue가 비었다고 인식하여
unlock을 하고 -1을 return 하도록 한다.
Concurrent Hash Table
단순하게 hash table에 focus를 두는 매커니즘이다.
hash table size는 변경되지 않고 위에서 살펴본 concurrent list를 사용함으로써 구성된다.
그리고 각 list에 의해 represent 되는 hash bucket 마다 lock을 사용한다.
#define BUCKETS (101)
typedef struct __hash_t {
list_t lists[BUCKETS];
} hash_t;
void Hash_Init(hash_t *H) {
int i;
for(i = 0; i < BUCKETS; i++) {
List_Init(&H->lists[i]);
}
}
int Hash_Insert(hash_t *H, int key) {
int bucket = key % BUCKETS;
return List_Insert(&H->lists[bucket], key);
}
int Hash_Lookup(hash_t *H, int key) {
int bucket = key % BUCKETS;
return List_Lookup(&H->lists[bucket], key);
}
(1) Hash_Init()
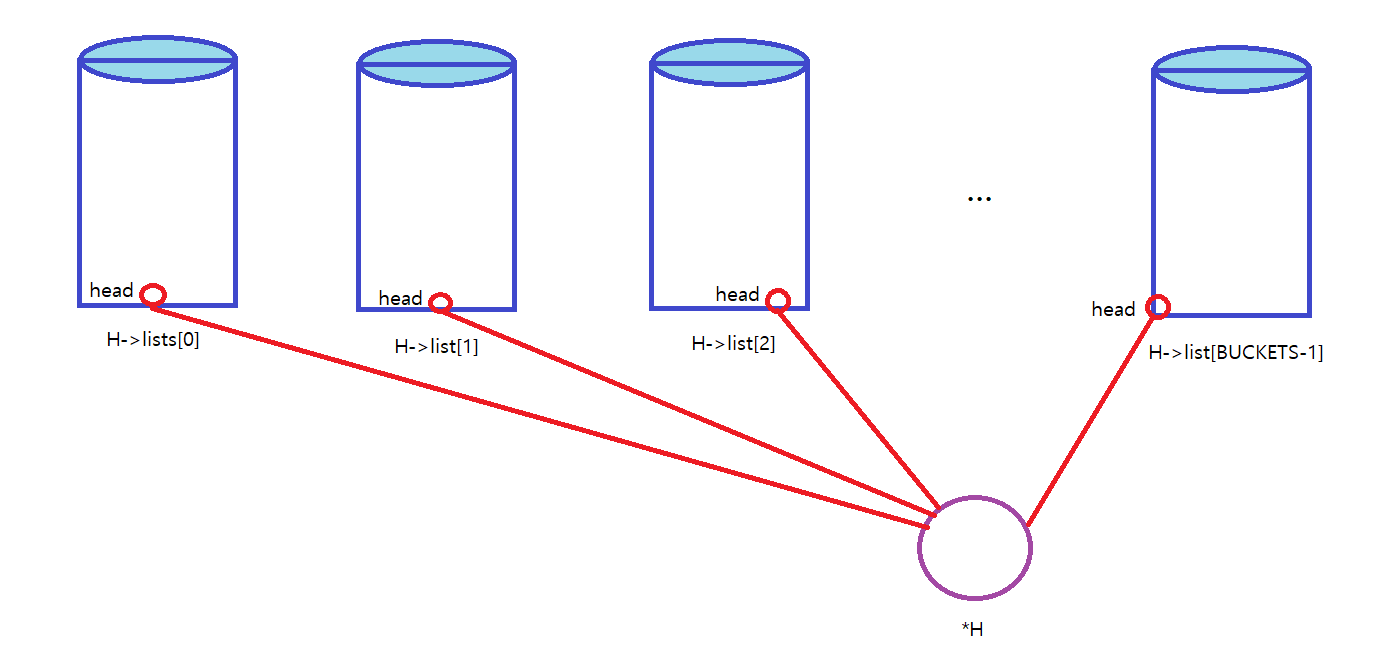
각 bucket 마다 list에 대한 초기화 (H->lists[i]->head = NULL, 쓰레드 초기화) 가 BUCKETS 만큼 일어난다.
(2) Hash_Insert()

key 값을 통해 bucket = key % BUCKETS, 즉, bucket 번째에 대한 Bucket 에 key 값을 해당 Bucket의 list에다가
삽입하도록 한다.
(3) Hash_Lookup()
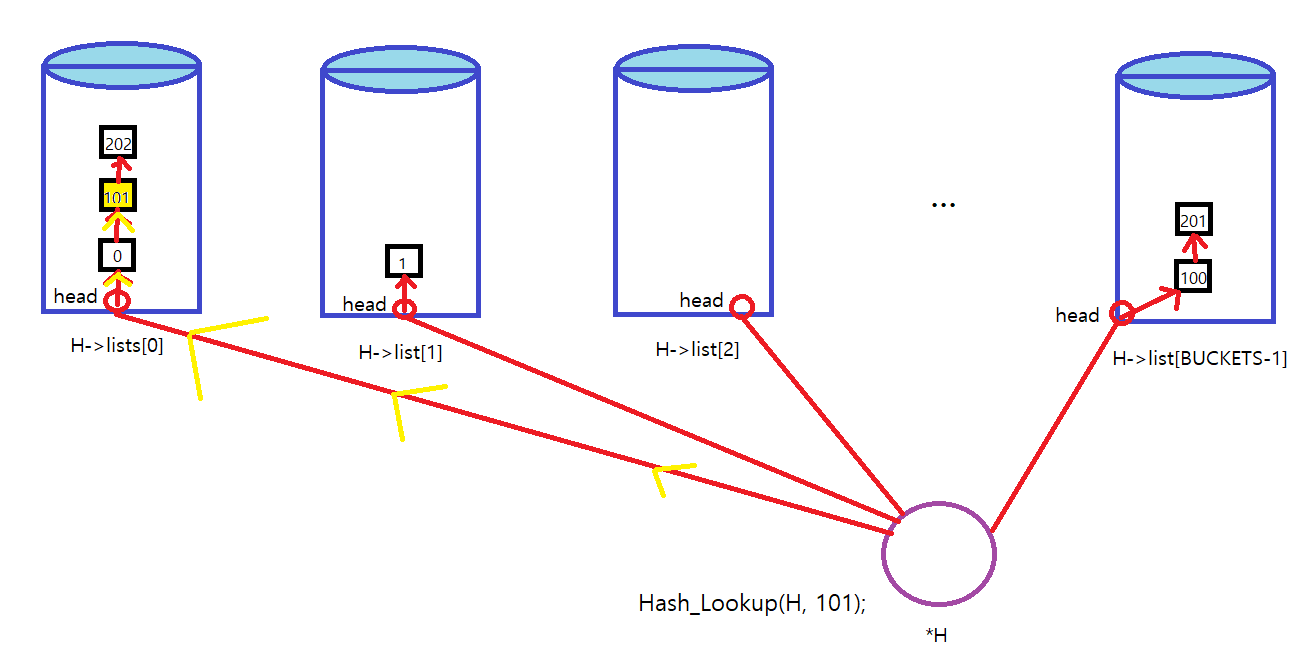
예를 들어서 Hash_Lookup(H, 101); 이 호출되었다고 하면 index가 0인 Bucket에 101 값을 찾는다.
key값을 찾을 경우 unlock을 하고 0을 리턴하고, 찾지 못할 경우 unlock을 하고 -1을 리턴한다.
Performance of Concurrent Hash Table
4개의 쓰레드로부터 10000개에서 50000개까지의 concurrent update가 일어났다고 하자.

확실히 단순하게 구현한 Concurrent List보다 Bucket을 이용하여 좀 더 세분화한 구현이 효율적임을
알 수 있다.
The simple concurrent hash table scales magnificently.
'학교에서 들은거 정리 > 운영체제' 카테고리의 다른 글
| Semaphore and Common Concurrency Problem (0) | 2021.11.18 |
|---|---|
| Conditional Variables (0) | 2021.11.12 |
| Swapping Policies (0) | 2021.10.29 |
| Swapping Mechanisms (0) | 2021.10.27 |
| Advanced Page Tables (0) | 2021.10.15 |



