
mojo's Blog
Multiprocessor Scheduling (Advanced) 본문
이전에 배웠던거에 이어서...
The Priority Boost
Rule 5 : After some time period S, move all the jobs in the system to the topmost queue.
Example ) A long-running job(A) with two short-running interactive job(B, C)
여기서 interactive job이란? => CPU를 짧게 사용하고 I/O를 하는 process를 의미함

왼쪽 예제를 보면 long job A를 실행하고 time slice를 초과하면서 Q0까지 이동하다가
short job B, C가 RR Scheduling 을 계속해서 하는 모습이다. (언제 끝날지 모름)
그렇다면 RR을 계속하는 과정에서 job A는 결국 오랜 시간동안 실행을 하지 못하는 즉, starvation
이 발생할 수 있다는 것이다.
Rule 5 를 적용하여 특정 주기 S가 지나면 오른쪽 사진처럼 job A를 올려주는 방식으로 starvation
이 발생하는 것을 방지할 수 있다.
How to prevent gaming of our scheduler?
Solution :
Rule 4 (Rewrite Rules 4a and 4b) : Once a job uses up its time allotment at a given level
(regardless of how many times it has given up the CPU), its priority is reduced.
(it moves down on queue)
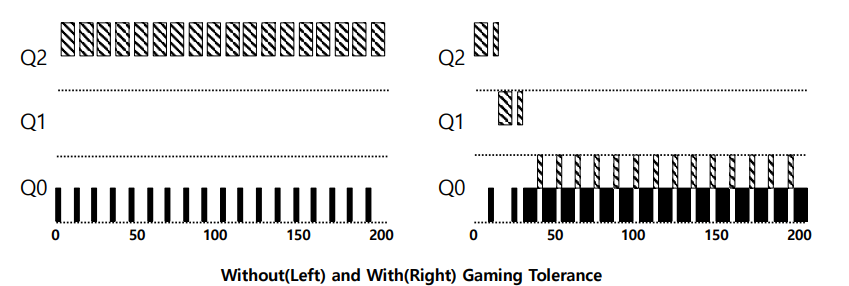
왼쪽 사진을 보면 Q2 에 존재하는 job 이 CPU를 99% 사용하다가 악의적으로 I/O를 실행하여
priority가 가장 높은 Q2에 계속 머물고 있는 상태임을 볼 수 있다.
즉 Q2의 time slice를 악의적으로 거의 끝까지 사용하다가 I/O를 실행하는 이러한 경우를 Gaming the
Scheduler 라 한다.
그래서 이러한 경우를 해결하기 위해서 해당 Queue에 주어진 특정 시간을 다 써버리는 경우 priority를
강등시켜서 Gaming the scheduler 를 방지할 수 있다.
Tuning MLFQ And Other Issues
The high-priority queues -> Short time slices (10 or fewer milliseconds)
The Low-priority queues -> Longer time slices (100 milliseconds)

The Solaris MLFQ implementation
For the Time-Sharing scheduling class (TS)
=> 60 Queues
=> Slowly increasing time-slice length
- The highest priority : 20msec
- The lowest priority : A few hundred milliseconds
=> Priorities boosted around every 1 second or so.
MLFQ 총 정리
Rule 1 : job A, B에 대해서 priority가 A가 더 크면 A를 실행시킨다.
Rule 2 : job A, B에 대해서 priority가 동일하면 Round Robins Scheduling 을 실행한다.
Rule 3 : job이 system에 들어갈 때, 가장 priority가 높은 Queue에 배치시킨다.
Rule 4 : job이 지정된 level에서의 모든 time allotment를 다 사용하게 된 경우 priority를 낮춘다.
Rule 5 : 일정 기간 S가 지나면 system의 모든 job들을 topmost queue로 이동한다.
Multiprocessor Scheduling
The rise of the multicore processor is the source of multiprocessor-scheduling proliferation(확산).
Multicore : Multiple CPU cores are packed onto a single chip.
Adding more CPUs does not make that single application run faster.
=> You'll have to rewrite application to run in parallel, using threads.

CPU 구조를 살펴보면 단일 CPU안에 Cache가 있다.
Cache는 Memory content 일부의 복제본을 가지고 있다.
그리고 동일한 복제본을 Cache가 가지고 있기 때문에 CPU가 load 명령어로 Memory에 접근할 때
Cache에 먼저 접근을 해서 해당 데이터가 있는지 없는지 확인한다.
=> Memory 접근 속도를 줄일 수 있음.
Cache의 용량이 작아서 필요에 따라 Memory에 접근을 해야 한다.
즉, Cache를 적극적으로 활용함으로써 CPU가 가장 빨리 실행하는 것처럼 보이게 하는 것이 바로
Cache의 역할이다.
Cache coherence
Consistency of shared resource data stored in multiple caches.
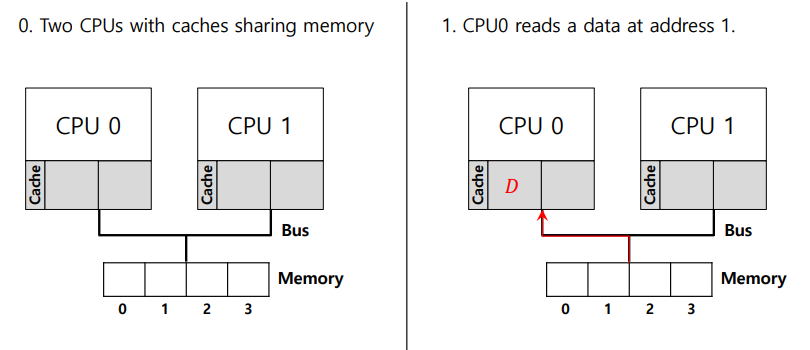
윗 사진을 통해 각 CPU마다 자기만의 Cache를 가지고 있음을 알 수 있다.
그리고 Memory Bus를 통해서 Memory를 공유하고 있다.
예를들어서 fork(), thread()를 실행하여 mapping이 되면서 돌아간다고 가정한다.
이때 CPU 0이 D라는 데이터를 읽어서 D를 업데이트하여 Cache 내에 업데이트한 D' 이 존재하게 된다.
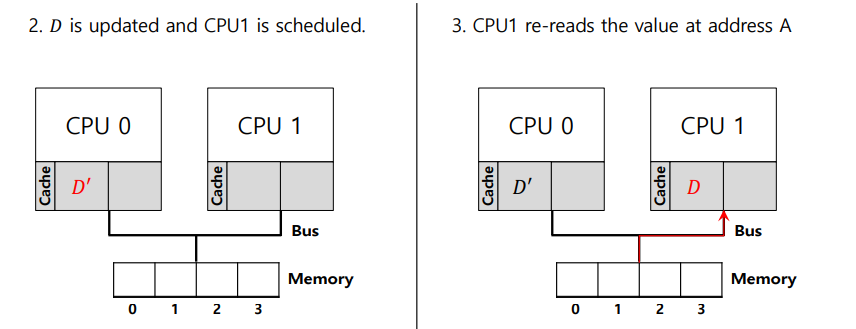
그리고 CPU1에서 다시 D를 읽으려고 하는데 CPU1 내의 Cache에 데이터가 없으므로 Memory로 이동해서
읽어온다. (CPU 별로 Private Cache를 지님)
그렇다면 Program order상 CPU 0에서 D' 로 변경되었는데 CPU 1에서 D를 읽으려고 하는데 Cache에
없기 때문에 Memory에 존재하는 그대로의 D 값을 읽어버린다. (잘못된 data)
즉, CPU1는 정확한 값 D'을 읽지 못하고 이전의 값 D를 읽어버림
이러한 문제를 Cache coherence Problem이라고 한다.
Cache coherence Solution
Bus snooping
- Each cache pays attention to memory updates by observing the bus.
- When a CPU sees an update for a data item it holds in its cache, it will notice
the change and either invalidate its copy or update it.
update 를 한다는 의미는 다음과 같다.
위 사진으로 CPU 1이 D를 읽을때 Cache에 D를 저장함과 동시에 CPU 0가 bus로 연결된 동일한
주소의 memory 상에 존재하는 D를 최신 버젼을 갖고 있음을 알리고 CPU 1에 존재하는 D를 D'으로
하드웨어적으로 update 해주는 것을 의미한다.
invalidate 를 한다는 의미는 다음과 같다.
Cache controller 끼리 메시지를 주고받으면서 해당 데이터를 invalidate를 할 수 있다.
이러한 update, invalidate 등의 Bus snooping이 Cache coherence 를 해결할 수 있는
Hard Solution 이다.
Don't forget synchronization
When accessing shared data across CPUs, mutual exclusion primitives should likely
be used to guarantee correctness.
typedef struct _Node_t {
int value;
struct _Node_t *next;
} Node_t;
int list_Pop(){
Node_t *tmp = head;
int value = head->value;
head = head->next;
free(tmp);
return value;
}
2개의 thread가 동일한 sharing struct에서 list_Pop() 하게되면 문제가 생긴다.
thread 1, thread 2에서 둘 다 list_pop을 부른 경우 각각 head를 읽어서 각각의 stack에 읽어드리는데
동시에 실행하다 보면 free를 2번 할 수 있다.
즉, 동일한 메모리를 둘 다 free를 해버리는 문제가 발생하고 2번 pop하게 되버린다.
다음 아이템을 pop 해야하는데 동일한 item 을 pop 해버리는 일이 발생하는 것이다.
예를 들어서 1 -> 2 -> 3 -> 4 처럼 연결되어 있다고 하고 thread 1, 2가 있다고 하자.
thread 1, 2가 1을 동시에 return 해버리는 일이 발생해버리고 만다. (1, 2를 return 해야 하는데?)
그래서 이를 해결하는 방법은 Synchronization 기법이다.
즉, lock을 이용하여 thread 하나만 들어갈 수 있도록 하는 것이다.
pthread_mutex_t m;
typedef struct _Node_t {
int value;
struct _Node_t *next;
}
int list_Pop() {
lock(&m);
Node_t *tmp = head;
int value = head->value;
head = head->next;
free(tmp);
unlock(&m);
return value;
}
Cache Affinity
Keep a process on the same CPU if at all possible.
- A process builds up a fair bit of state in the cache of a CPU.
- The next time the process run, it will run faster if some of its state is already present
in the cache on that CPU.
Single queue Multiprocessor Scheduling (SQMS)
Put all jobs that need to be scheduled into a single queue.
Each CPU simply picks the next job from the globally shared queue.
- Some form of locking have to be inserted => Lack of scalability
- Cache affinity
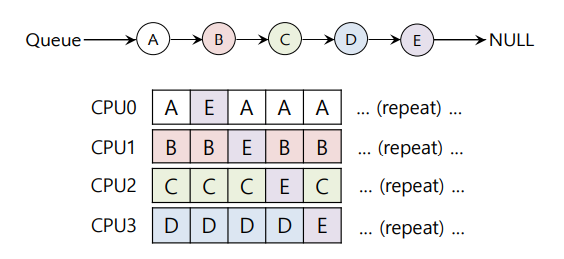
왼쪽같은 경우는 Cache coherence problem 이 생겼다는 것을 알 수 있다.
즉, overhead가 굉장히 증가하게 되버린다.
오른쪽 같은 경우는 job E를 희생시킴으로써 Cache coherence problem을 해결할 수 있다.
그러나 구현하기에는 복잡하다.
Multi-queue Multiprocessor Scheduling (MQMS)
MQMS consists of multiple scheduling queues.
- Each queue will follow a particular scheduling discipline.
- When a job enters the system, it is placed on exactly one scheduling queue.
- Avoid the problems of information sharing and synchronization.
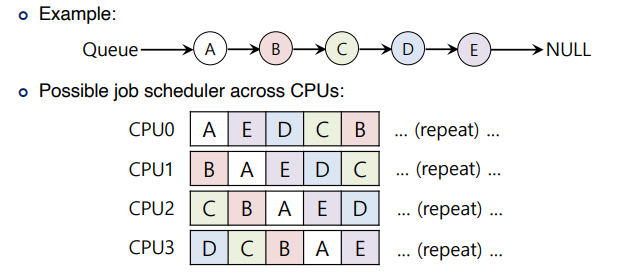
With round robin, the system might produce a schedule that looks like this
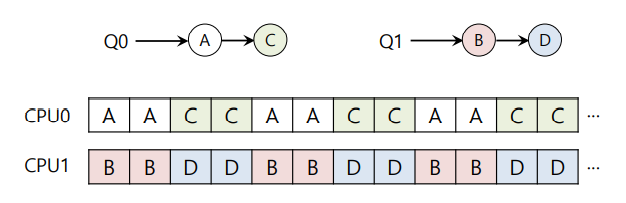
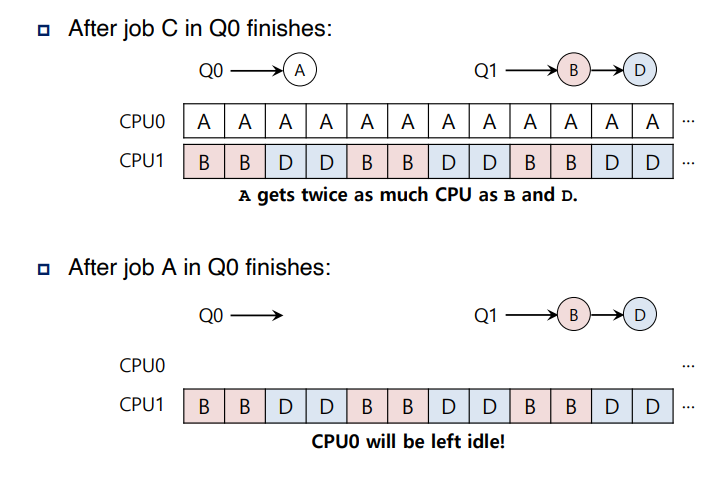
오른쪽 사진을 보면 Q0 에 job C, A 순으로 끝나면 CPU 0는 idle 상태이고 CPU 1은 여전히 busy 상태이다.
이러한 unbalance 를 어떻게 해결해야 할까?
=> job을 Migration 하는 기법을 이용한다.
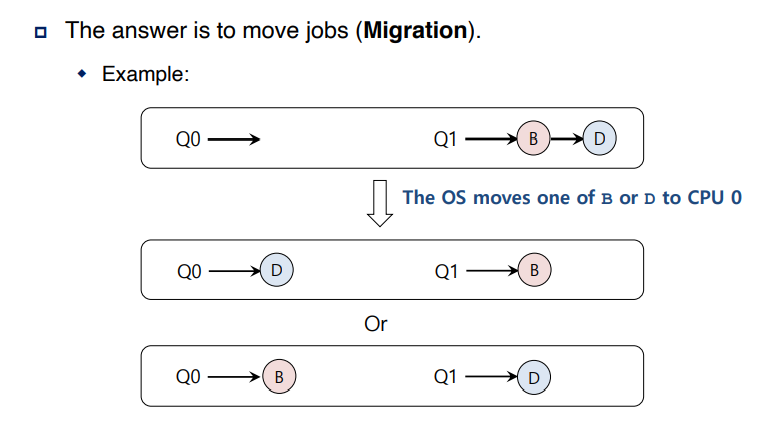
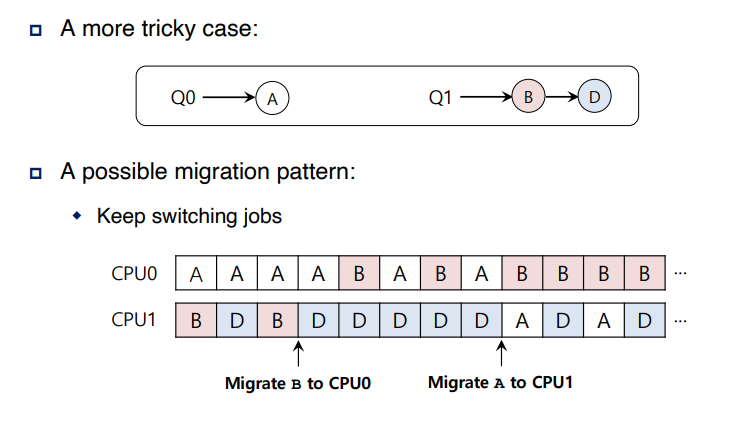
왼쪽 같은 경우는 Q0 이 심심하지 않게 Q1 에 존재하는 job B 또는 D를 Q0 에 migrate 하는 방법이다.
또한 오른쪽과 같이 CPU 내에서 job B를 CPU 0으로 migrate하고 job A를 CPU 1으로 migrate 하는
방법도 존재한다.
'학교에서 들은거 정리 > 운영체제' 카테고리의 다른 글
| Memory API, Segmentation (0) | 2021.10.07 |
|---|---|
| Address Translation (0) | 2021.10.01 |
| Memory Virtualization (0) | 2021.09.30 |
| The Multi-Level Feedback Queue (0) | 2021.09.17 |
| Scheduling (0) | 2021.09.16 |



