
mojo's Blog
Scheduling 본문
Scheduling Metrics
시작에 앞서 4가지 가정이 있다고 하자.
1. Each job runs for the same amount of time.
ex) process p1, p2, p3, p4 가 동일하게 10초씩 돈다고 가정
2. All jobs arrive at the same time.
ex ) CPU 입장에서 동시에 실행해서 도착한 상황이라고 가정
3. All jobs only use the CPU (they perform no I/O)
4. The run-time of each job is known.
Performance metric : Turnaround time
=> The time at which the job completes minus the time at which the job arrived in the system.
Time(turnaround) = Time(completion) - Time(arrival)
Another metric is fairness
=> Performance and fairness are often at odds in scheduling.
모든 process가 균등하게 CPU 제어를 받을 권한이 있어야 한다.
즉 fairness, 하나라도 할당받지 못하면 안된다.
FIFO
First Come, First Served (FCFS)
=> Very simple and easy to implement
예를 들어서 3 개의 Process A, B, C 가 있다고 가정하자. (각각 10초씩 걸린다고 가정)
A 가 먼저 CPU 를 점유할 때, B, C는 A가 끝날때까지 기다려야 한다.
A 가 딱 10초를 썻을 경우 B, C 중에 B 가 선택되면 B 가 10초를 쓰고 C 는 20초나 기다려야 한다.
즉 이러한 경우는 다음과 같다.

Average turnaround time = (10 + 20 + 30) / 3 = 20 sec
fairness 관점으로 바라보자.
Turnaround time(A) = 10 <= 평균 시간보다 빠르므로 이득
Turnaround time(B) = 20 <= 평균과 같음
Turnaround time(C) = 30 <= 평균 시간보다 느리므로 손해
여기서 C는 평균 시간보다 느리므로 fairness 가 존재하지 않음.
"왜 FIFO 구조는 좋지 않을까?" 라는 의문을 던져보기 위해 위에서 세웠던 가정 중 1을 relax 하려고 한다.
Let's relax assumption 1
=> Each job no longer runs for the same amount of time.
예를 들어서 3 개의 Process A, B, C 에서 A는 100, B는 10, C는 10이 걸린다고 하자.
이때 A를 long job, B를 short job 이라고 할 수 있겠다.
근데 A, B, C 순서로 Process 가 도착할 경우 long job이 먼저 실행되므로 short job은 long job이 끝날때까지 기다려야 한다.
즉, 이러한 경우는 다음과 같다.
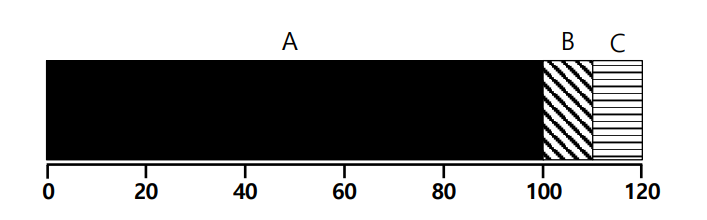
Average turnaround time = (100 + 110 + 120) / 3 = 110 sec
Convoy effect
Suppose there is one CPU intensive process in the ready queue, and several other
processes with relatively less burst times but are Input/Output (I/O) bound.
(여기서 I/O bound 는 CPU 를 조금 점유한다고 봐도 될듯함)
다음과 같은 가정속에서 process 10개, p1, p2, ..., p10 이 존재한다고 하자.
long job p1 : CPU intensive (cpu(99%), I/O(1%)) 이 경우 굉장히 오래 실행됨.
short job p2~10 : I/O intensive (cpu(5%), I/O(95%)) 이 경우 굉장히 적게 실행됨.
FIFO 구조로 p1 => p2 => ... => p10 순서로 process가 도착했다고 가정하자.
p1 이 먼저 Running state 이므로 p2~10 는 Ready state 이다.
p1 이 CPU를 점유가 끝나기 전까지 p2~10 는 실행하지 못하는 상태고 p1 이 I/O 하기 전까지
CPU 는 busy 한 상태이며 Disk 는 Idle 한 상태이다.
그리고 CPU 점유가 끝나면 I/O 상태로 변하면서 p1 는 Blocked state 로 변경된다.
그러면 다음 순서로 p2가 넘어오는데 CPU 를 굉장히 조금 쓰기 때문에 바로 Blocked state 가 된다.
그렇다면 p1, p2 는 blocked state이며 그다음 순서로 p3 이 넘어오는데 이러한 과정이 반복된다.
즉, p1~10 이 Blocked 상태로 아까와 반대 상황으로 CPU 가 idle 상태이며 Disk 는 Busy 상태가 된다.
이러한 상태를 Convoy Effect 라고 한다.
따라서 CPU, I/O Device 가 모두 Busy 상태인 경우가 가장 이상적인 상태이다.
하지만, Convoy Effect 가 발생하면 하나의 디바이스만 Busy 하고 다른 디바이스가 Idle 한 상태가 발생한다.
Passing the Tractor
Problem with Previous Scheduler
=> FIFO : Turnaround time can suffer when short jobs must wait for long jobs.
Tractor 는 FIFO 구조이기 때문에 어떤 process가 긴 시간동안 CPU 점유를 한다면
나머지 job 들을 기다려야 한다.
그래서 나온 Scheduler 는 2개가 존재한다.
New Scheduler
1. SJF (Shortest Job First)
2. Choose job with smallest run_time
Shortest Job First (SJF)
Run the shortest job first, then the next shortest and so on
=> Non-preemptive(선제적인) scheduler
예를 들어서 B(10) => C(10) => A(100) 순서로 process 가 동시에 도착했다고 하자.

이 경우에는 Average turnaround time = (10 + 20 + 120) / 3 = 50 sec 이다.
근데 이렇게 구할 수 있는 방법은 각 process 들의 실행시간을 알아야하는데 모른다는게 문제다.
즉, 이렇게 모든 process 들의 실행시간을 안다면 효율적으로 돌릴 수 있다.
SJF with Late Arrivals from B and C
이제 2번째 가정을 relax 하도록 해보자.
Let's relax assumption 2 : Jobs can arive at any time.
즉, 동일한 시간에 Process가 도착하는게 아니라 랜덤한 시간에 도착한다고 한다.
A 가 0 sec에 도착하고 run 하는데 100 이 걸린다고 하고
B, C 는 10 sec 에 도착하고 run 하는데 10 이 걸린다고 하자.
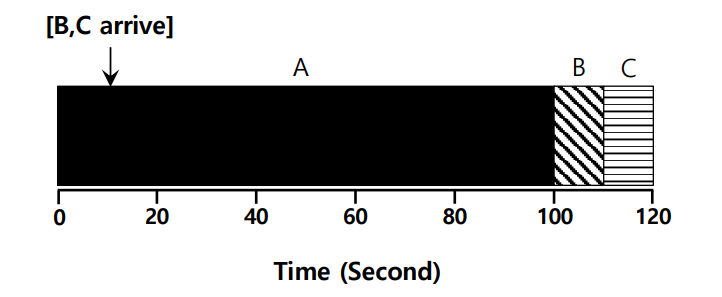
이 경우에는 Average turnaround time = (100 + (110 - 10) + (120 - 10)) / 3 = 103.33 sec 이다.
도착시간이 모두 같은 경우 110 sec 인데 약간의 delay 가 있는 경우 103.33 sec 으로 줄어든 모습이다.
Shortest Time-to-Completion First (STCF)
Add preemption to SJF
=> Also knows as Preemptive Shortest Job First (PSJF)
A new job enters the system
- Determine of the remaining jobs and new job
- Schedule the job which has the lest time left
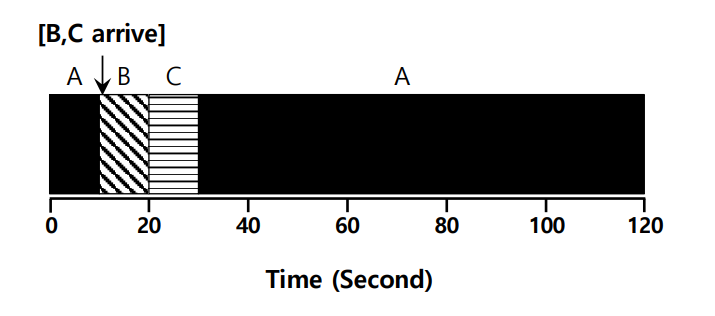
예를 들어서 process B, C가 ready Queue 에 들어오는 순간 run 시간을 비교한다.
A 를 preemtion 으로 돌리고 B, C를 돌리고 다시 A 를 돌린다. (B, C 는 10 sec run 하므로)
Average turnaround time = (120 + (20 - 10) + (30 - 10)) / 3 = 50 sec 이다.
New scheduling metric : Response time
The time from when the job arrives to the first time it is scheduled.
Time(response) = Time(firstrun) - Time(arrival)
STCF and related disciplines are not particularly good for response time.
Round Robins Scheduling
Time slicing Scheduling
- Run a job for a time slice and then switch to the next job in the run queue until the
jobs are finished. => Time slice is sometimes called a scheduling quantum.
(여기서 scheduling quantum = time quantum = 약 10ms)
- It repeatedly does so until the jobs are finished.
- The length of a time slice must be a multiple of the timer-interrupt period.

The shorter time slice VS The longer time slice
The shorter time slice
- Better response time
- The cost of context switching will dominate overall performance.
The longer time slice
- Amortize the cost of switching
- Worse response time
Incorporating I/O
이제 3번째 가정을 제거해보도록 한다.
Let's relax assumption 3 : All programs perform I/O
- A and B need 50ms of CPU time each.
- A runs for 10ms and then issues an I/O request (I/Os each take 10ms)
- B simply uses the CPU for 50ms and performs no I/O
- The scheduler runs A first, then B after

위 경우와 아래 경우중에 위 경우는 빈 공간을 사용하지 않아 굉장히 비효율적으로 보인다.
그래서 I/O 하는 동안에 CPU가 점유하지 않는 동안에 다른 Process를 Scheduling 하도록 해야 한다.
즉, CPU utilization 을 좀 더 maximize 할 수 있다.
그래서 job 이 I/O request 를 하면 job 이 blocked 되고 Scheduler가 다른 job 을
CPU 점유를 하도록 하게 한다.
When the I/O completes
- An interrupt is raised.
- The OS moves the process from blocked back to the ready state.
'학교에서 들은거 정리 > 운영체제' 카테고리의 다른 글
| Memory API, Segmentation (0) | 2021.10.07 |
|---|---|
| Address Translation (0) | 2021.10.01 |
| Memory Virtualization (0) | 2021.09.30 |
| Multiprocessor Scheduling (Advanced) (0) | 2021.09.24 |
| The Multi-Level Feedback Queue (0) | 2021.09.17 |



