
mojo's Blog
Basics of Machine Learning 본문
※ What is Machine Learning?
A field of study that lets computers have the ability to learn by themselves
without being explicitly programmed.
=> 머신러닝은 명시적인 규칙 없이 스스로 학습한다는 것으로,
주어진 data로 자기 스스로 관계를 추론하는 관계를 찾아내는 컴퓨터 프로그래밍이다.
A computer program to learn from experience E with respect to some class of
tasks T and performance measure P, if its performance at tasks in T, as measured by P,
improves with experience E.
=> 머신러닝은 주어진 task가 어느 방향으로 성능 개선이 되는지에 대한 measure가 결정될 때,
어떤 경험이 축적됨에 따라서 컴퓨터 프로그램 스스로 점점 더 나은 방향으로 학습할 수 있는
컴퓨터 프로그램이다.
A study of computer algorithms that allow computer program to automatically
improve through experience.
=> 경험은 data, task는 supervised learning에 속하는 classification,
그리고 performance measure는 accuracy 등이 될 수 있다.
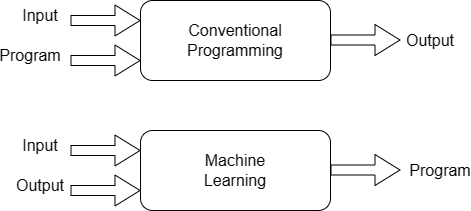
※ Conventional vs. Machine Learning
※ Examples of Machine Learning
(1) 어떤 그림을 보고 집인지 고양이인지 강아지인지를 맞추는 분류 문제
(2) 임의의 자연어가 들어올 때 텍스트 평점을 판단하는 문제
(3) 임의의 벡터가 들어올 때 어떤 영상을 생성해내는 것
※ Types of Machine Learning


Given a set of input data \(X = { x^{1}, x^{2}, ..., x^{n} }\),
Supervised Learning
We are also given target outputs (labels, responses): \(Y = { y^{1}, y^{2}, ..., y^{n} }\)
The goal is to predict correct output given a new input.
=> X와 Y의 관계를 추론하는 것이 주 목적이다.
Unsupervised Learning
We only have a set of input data X.
The goal is to discover hidden representation of data.
=> 아웃풋 없이 오직 인풋만으로 데이터의 숨겨진 의미 있는 어떤 표현 방법을 찾는 것이 주 목적이다.
Reinforcement Learning
Given a state s ∈ S, the model (agent) produces a set of actions, \(a_{1}, a_{2}, ..., a_{k}\)
that affect the next state s' ∈ S and rewards \(r_{1}, r_{2}, ..., r_{k}\)
The goal is to learn actions in an environment to maximize cumulative rewards.
=> 보상을 최대화하도록 action 을 취하는 것이 강화학습의 목적이다.
Supervised Learning
※ What is Supervised Learning?
Data consist of input-output pairs.
- Input: covariates, predictors, and features
- Output: variates, targets, labels
Let computers learn with many (input, output) pairs.
- The output are direct feedback for given input.

Regression vs. Classification
- Regression: Labels are continuous. (실수 value 를 가질 때)
- Classification: Labels are discrete. (정수 value 를 가질 때)
※ Regression Models
Predicting real values (i.e., continuous labels)
Ex)
- Linear regression: X와 Y의 관계를 어떤 선형관계로 표현하여 Y에 대한 레이블을 맞추는 것
- Polynomial regression: X와 Y의 레이블이 다항식 관계를 가진 경우 (2차 이상)
※ Classification Models
Predicting categorical values (i.e., discrete labels)
- It learns decision boundaries for data with different labels.
Ex)
- Logistic regression, Support vector machines (SVM)
- Neural Networks: Perceptron, Multilayer perceptron (MLP)
- Decision trees, Naive Bayes, K-nearest neighbors (k-NN)
Unsupervised Learning
※ What is Unsupervised Learning?
Finding hidden patterns in a dataset with no labels and with a minimum
of human supervision
=> Unsupervised Learning 은 output 없이 숨겨진 패턴을 찾는것이 주 목적이다.

가장 중요한 것은 기본적으로 data의 레이블이 제공되지 않기 때문에,
이 data를 어떻게 해석하면 좋은지에 대해서 기본적인 최소한의 어떤 가이드라인이 제공되어야 한다.
Finding hidden meaningful representations of data
Clustering
Discover groups of similar examples within the data.
-> E.g., K-means clustering
Dimensionality reduction
Project the data from a high-dimensional space to a lower dimension space.
-> E.g., Principle Component Analysis (PCA)
Density estimation
Determine the distribution of data within the input space.
-> E.g., Gaussian Mixture Model (GMM)
※ Clustering
Grouping similar data tuples into clusters
- Defining the similarities between data according to the characteristics found in the data
Cluster : A group of data instances
- Similar (or related) to one another within the same group
- Dissimilar (or unrelated) to the tuples in other groups
※ Dimensionality Reduction
Assume that a D-dimensional data lie on or near a d-dimensional subspace.
How to represent the axes of subspace effectively?
2차원의 X, Y로 구성된 data를 하나의 차원으로 표현할 수 있다. (3차원 그 이상도 가능)
차원을 축소하는 이유로는 다음과 같다.
(1) 고차원의 data에서는 알 수 없었던 feature 간의 숨겨진 연관관계 좀 더 효과적으로 이해할 수 있도록 함
(2) feature들 중에서 redundant 하거나 noisy한 feature를 효과적으로 제거할 수 있도록 함
(3) 저장공간이나 data 처리에 대해서 이점을 갖도록 함
(4) 고차원에서 저차원으로 축소하여 시각화나 해석 능력에 도움이 되도록 함
※ Density Estimation
Given input data \( x_{1}, x_{2}, ..., x_{n}\) sampled by an unknown distribution P(X),
estimate z associated with P(X).
Reinforcement Learning
※ What is Reinforcement Learning?
Learning agents to take actions in an environment to maximize cumulative rewards.
(agent는 특정한 상태에 대해 액션을 취함)
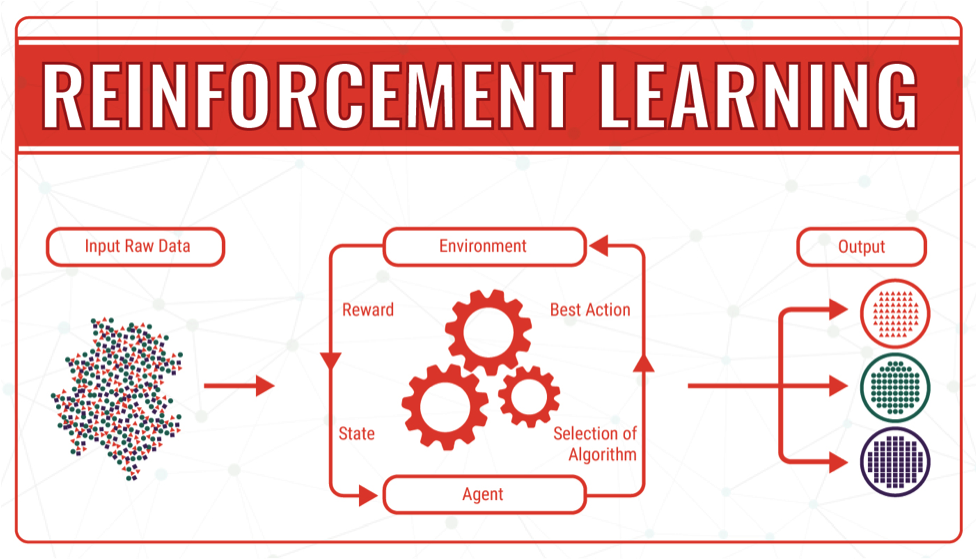
reward가 최대화되는 방향으로 액션을 선택하게끔 학습을 하는 것이 주된 목적이다.
supervised learning 에서 (x, y) 가 (s, a) 로 바라볼 수 있다. (s - state, a - action)
그리고 y = f(x)가 아닌 f(s, a) = r 으로 r 값을 최대화 하는 것이 주된 목적이다. (r - reward)
Computational approach to learning from interaction
- 주어진 sequential data에서 가장 좋은 판단을 하는 것을 학습하는 것
- 환경에 의해서 reward 를 기반으로 최적의 액션을 뽑아내는 것
- 약간의 delay가 존재할 수 있음
- 매 state마다 취한 액션은 추후에 reward에 영향을 줌
'머신러닝' 카테고리의 다른 글
| Classification Problem (0) | 2023.03.19 |
|---|---|
| Linear Regression Models (0) | 2023.03.19 |
| Gradient Descent Method (0) | 2023.03.16 |
| Steps of Supervised Learning (0) | 2023.03.14 |
| Deep Learning Basic (0) | 2023.03.14 |



