
mojo's Blog
Target code generation - (1) 본문
Machine-dependent Optimization
기계 종속적 최적화 기법Machine-dependent Optimization
● 기계의 특성에 따라 달라질 수 있음
● 중복 명령어 제거, 효율적인 명령어 선택, 레지스터 할당과 배정, 명령어 스케줄링 등이 있음
중복 명령어 제거
● 핍홀 최적화 기법에서 사용하는 것과 동일
● 중복되는 로드 명령문이나 저장 명령문을 제거함으로써 최적화하는 방법
효율적인 명령어 선택
● 동일한 기능을 가진 더 효율적인 명령어로 대치함으로써 최적화하는 방법
● ex) 소스코드 x = x + 1에 대한 명령어는 다음과 같다:
LOAD R1, x
ADD R1, 1
STORE x, R1
컴퓨터가 레지스터나 메모리에서 1을 증가시키는 INC(increase) 명령어를 가질 경우:
INC x
레지스터 할당과 배정
● 목적 코드의 생성에서 중요한 고려 대상 중의 하나는 레지스터를 어떻게 이용하느냐 하는 것
○ 레지스터는 메모리보다 액세스(access)가 빠르고 저장과 로드를 위한 명령이 필요없음.
● 그러나 레지스터의 수는 극히 한정되어 있으므로 레지스터 할당 방법이 문제가 된다.
지역적 할당 방법과 전역적 할당 방법
● 지역적 할당 방법은 프로그램을 기본 블록으로 분할했을 때 각 기본 블록 내에서 변수를 레지스터에 할당하는 방법 ● 전역적 할당 방법은 전체 프로시저를 고려하여 할당하는 방법
레지스터 할당 방법
● 그래프 착색(graph coloring) 방법으로 NP 완전(NP-complete) 문제
● 경험적인 방법에 따라 할당하되,
○ 전역적으로 잘 사용되는 자료는 되도록 레지스터에 넣어두는 편이 좋고,
○ 지역적으로는 한 번 레지스터로 꺼내온 자료를 되도록 그곳에 보관하고 이용하는 편이 좋음
명령어 스케줄링
● 연산 순서 변경에 의해 임시 결과(temporary result)에 대한 저장(STORE), 로드(LOAD)의 횟수를 최소로
함으로써 임시 변수 기억 공간을 절약
Example) 하나의 레지스터로 효율적인 명령어 만들기
산술식 A * B - C * D를 계산하는 데 하나의 레지스터 R0만을 이용할 수 있고, 일반적인 연산자 우선순위라고
가정하면 다음과 같이 8개의 명령을 갖는다.
식의 순서를 변경하여 효율적인 명령어를 만들어보자.
LOAD R0, A
MULT R0, B
STORE temp1, R0
LOAD R0, C
MULT R0, D
STORE temp2, R0
LOAD R0, temp1
SUBT R0, temp2
C * D 를 먼저 하는게 더 효율적으로 보인다.
LOAD R0, C
MULT R0, D
STORE temp1, R0
LOAD R0, A
MULT R0, B
SUBT R0, temp1
Target Code Generation
목적 코드 생성(target code generation): 컴파일러의 마지막 단계
● 중간 코드와 기호표의 정보를 받아서 중간 코드 형태의 프로그램을 목적 기계에 맞는 기계어로 생성하거나
어셈블리어로 생성
● 목적 코드 생성기target code generator: 목적 코드 생성을 담당하는 도구
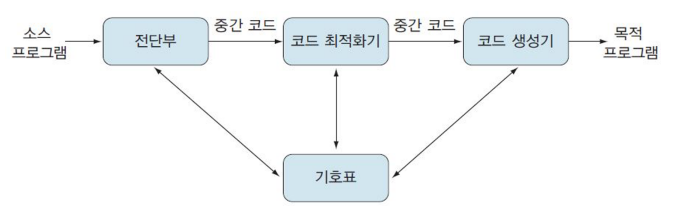
Target Code Generator
목적 코드 생성기: 명령어 선택, 명령어 스케줄링, 레지스터 할당과 배정 등을 수행
● 명령어 선택: 목적 기계에 따라 적절한 명령어를 선택
○ 대부분의 경우 같은 연산에 대해 다양한 명령어가 있는데 그 중 무엇을 선택할지 결정할 필요가 있음
● 레지스터 할당과 배정: 프로그램의 각 명령어가 어느 레지스터에 저장되어야 하는 지 결정
○ 어떤 피연산자를 어떤 레지스터에 어떻게 배정할 것인지에 대한 것이며, 일반적으로 메모리보 다 레지스터를
사용하면 연산 속도가 빠르므로 연산에 레지스터를 많이 사용할 수 있도록 설계
● 명령어 스케줄링: 명령어들의 실행을 어떤 순서로 나열할지 결정
○ 연산 순서에 따라 레지스터의 개수나 메모리의 요구량이 달라지기 때문에, 어떤 순서로 계산 과정을 수행할지
결정할 필요가 있음
Target Machine
목적 컴퓨터: n개의 범용 레지스터 R0, R1, …, Rn-1을 가진 바이트 주소 가능 기계(byte-addressable machine)
● 로드와 저장 연산, 계산 연산, 분기 연산, 조건 분기를 가진 3-주소 기계를 모델링한다.
● 대부분의 명령어는 하나의 연산자와 다음에 오는 하나의 목적 피 연산자, 그 다음에 오는 소스 피연산자로 구성
목적 컴퓨터는 다음과 같은 명령어가 사용된다고 가정한다.
● 로드(LOAD) :
○ LOAD dst, addr은 addr 위치에 포함된 값을 dst 위치에 적재한다.
○ LOAD R1, R2는 레지스터 R2의 내용을 레지스터 R1에 복사한다.
● 저장(STORE) :
○ STORE x, R0은 레지스터 R0에 포함된 값을 x에 저장한다.
○ OP R1, R2, R3 : OP는 ADD, SUBT, MULT와 같은 연산자이고 R3 ← R1 + R2 이다.
○ OP R1, R2, R2 인 경우 OP R1, R2로 사용한다.
● 무조건 분기(unconditional jump) :
○ 명령어 BR L은 제어가 라벨 L로 이동한다. BR은 branch를 나타낸다.
○ 조건 분기(conditional jump) : 명령어 Bcond R, L은 R의 값이 조건(cond)에 맞으면 라벨 L로 분기하라는 것
○ BLTZ R, L은 R의 값이 0보다 작으면 라벨 L로 분기하라는 것
Example
다음 3-주소 문장을 레지스터 R0 하나만 사용해서 목적 코드로 변환 해보자.
x = y + z
u = x + v
LOAD R0, y
ADD R0, z, R0
STORE x, R0
ADD R0, v, R0
STORE u, R0
Example
3-주소 문장 x = y - z에 대해 레지스터를 2개 사용하여 기계 명령어로 변환해보자.
LOAD R1, y
LOAD R2, z
SUBT R1, R2, R1
STORE x, R1
명령어 선택
목적 프로그램의 효율성을 고려하지 않는다면 명령어 선택은 매우 간단하다.
예를 들어 x = y + z 형식(여기서 x, y, z는 정적으로 할당된다)에 해당하는 3-주소 문 장은 다음과 같은 코드로 변환될 수 있다.
LOAD R0, y
ADD R0, z, R0
STORE x, R0
이러한 기법은 대개 로드(LOAD)와 저장(STORE) 명령어를 중복되게 생성한다.
예시)
x = y + z
u = x + v
LOAD R0, y
ADD R0, z, R0
STORE x, R0
LOAD R0, x
ADD R0, v, R0
STORE u, R0
● 여기서 네 번째 문장은 이미 R0에 x가 있으므로 불필요하고
● 세 번째 문장도 x가 다음에 사용되지 않으면 불필요하다.
Tree Pattern Matching
명령어 선택 기법 가운데 가장 많이 사용되는 트리-패턴 매칭 기법에 대해 살펴보자.
트리-패턴 매칭 기법을 사용하면 명령어 선택을 쉽게 표현할 수 있다.
코드 생성을 트리-패턴 매칭으로 변환 하려면 중간 코드 형태의 프로그램과 목적 기계의 명령어 집합이 트리로
표현되어야만 한다.
트리-패턴 매 칭 규칙은 (식)과 같다.
Template→ Replacement {Action} … (식)
● Template: 트리
● Replacement: 단일 노드
● Action: 코드
예를 들어 레지스터-레지스터 덧셈 명령어에 대한 규칙을 생각해보자.
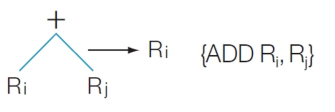
이 규칙은 입력 트리가 (식)의 템플릿과 매칭되는 부분 트리를 포함한다.
● 트리의 루트는 + 연산자이다. 왼쪽 자식노드가 레지스터 Ri, 오른쪽 자식노드가 레지스터 Rj라면 이 부분 트리를
단일 노드 Ri로 대체한 뒤 명령어 ADD Ri, Rj를 출력하는데, 이러한 대체를 부분 트리의 타일링(tiling)이라 한다.
트리-패턴 매칭 기법 예시:
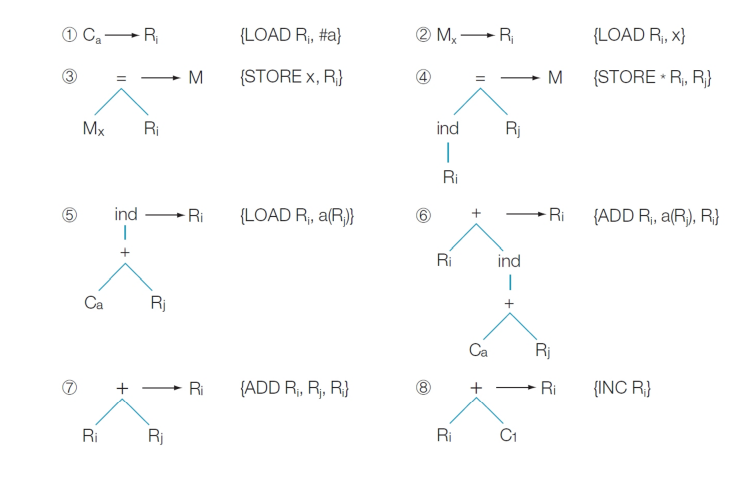
트리-패턴 매칭 기법의 동작 방식:
● 하나의 입력 트리가 주어지면 트리-패턴 매칭 기법의 템플릿이 부분 트리에 적용된다.
● 한 템플릿이 매칭되면 입력 트리에 속한 매칭되는 부분 트리가 해당 규칙에 의해 대체되고, 그 규칙에 연관된
action이 수행된다.
● Action이 일련의 기계 명령어를 포함하고 있으면 그 명령어들이 생성된다.
이러한 과정을 트리가 하나의 노드로 대체될 때까지 또는 더 이상 템플릿이 매칭되지 않을 때까지 반복한다.
입력 트리가 단일 노드로 reduce되면서 생성된 기계 명령 어들의 순서는 주어진 입력 트리상에서 트리-패턴
매칭 기법의 출력을 구성한다.
Example
치환문 a[i] = b + 1에 대한 중간 코드 트리를 만들어보자.
● 지역 변수 a와 i는 현재 활성 레코드의 시작을 가리키는 포인터인 스택 포인터로부터 상수 오프셋 Ca(Consta)와
Ci (Consti) 를 가지고 있는 지역 변수
● 배열 a는 실행 시간 스택에 저장된다.
● 배열 a와 변수 i의 주소는 각각 상수 Ca와 Ci 의 값을 레지스터 스택 포인터의 내용에 더함으로써 주어진다.
● 계산을 간단히 하기 위해 모든 값이 1바이트 문자라고 가정한다.
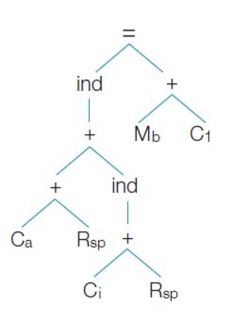
ind는 index로 i를 의미하며 밑에있는거 전부 다 메모리 주소를 의미함 (맨 위 ind 밑에 있는거)
중간 코드 생성은 다음과 같다.
1. Ca -> R0 (i가 0부터 시작한다고 가정)
{LOAD R0, #a}

2. {ADD R0, Rsp, R0}
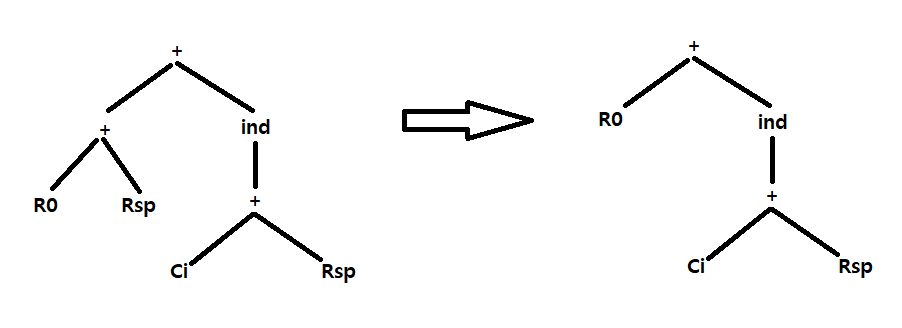
3. {ADD R0, i(Rsp), R0}

4. {LOAD R1, b}
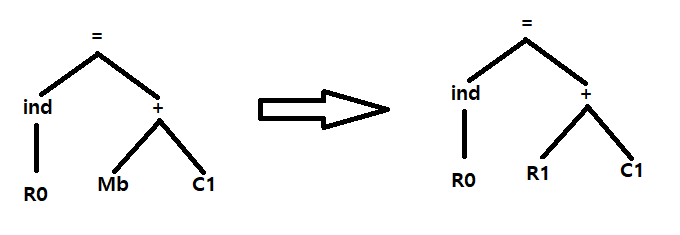
5. {INC R1}
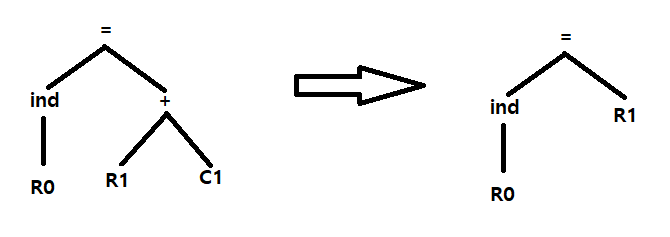
6. {STORE *R0, R1}
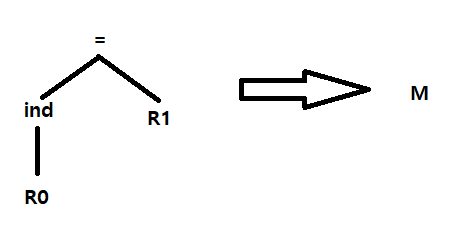
LOAD R0, #a
ADD R0, SP, R0
ADD R0, i(SP), R0
LOAD R1, b
INC R1
STORE *R0, R1
Code Generation
산술식에 대한 목적 코드 생성: 시스템 구조에 따라 달라짐
● 예시) 연산 레지스터가 1개이고 중간 언어가 트리 구조일 때, 목적 코드를 생성하는 방법은 [알고리즘]과 같다.
[알고리즘] 연산 레지스터 1개를 사용하여 트리 구조로부터 목적코드 생성
● [입력] 중간 언어로 트리 구조(단, 연산 레지스터를 Acc로 표현한다)
● [출력] 산술식에 대한 목적 코드 생성
● [방법]
1. 트리에서 루트로부터 순회한다.
2. 목적 코드 생성 루틴 호출하는 경우:
● 왼쪽 부분 트리가 하나의 변수이고 오른쪽 부분 트리가 하나의 변수이거나 Acc 또는 wi이면 목적 코드 생성 루틴을 호출한다.
● 왼쪽 부분 트리가 Acc이고 오른쪽 부분 트리가 하나의 변수나 wi이면 목적 코드 생성 루틴을 호출한다.
● 왼쪽 부분 트리가 부분 트리이고 오른쪽 부분 트리가 Acc이면 목적 코드 생성 루틴을 호출한다.
이외에는, 2개의 부분 트리 중 한쪽이 하나의 변수이거나 Acc 또는 wi이면 다른 쪽 부분 트리를 순회한다.
이때 부분 트리에 대해 루트와 왼쪽 부분 트리, 오른쪽 부분 트리의 이름을 T, L, R로 다시 정의한다.
3. 2개의 부분 트리가 모두 터미널 노드가 아니면 오른쪽 부분 트리를 먼저 순회한다.
4. 계속 같은 방법으로 순회하다가 양쪽의 부분 트리가 모두 터미널 노드이면 목적 코드 생성 루틴을 호출한다.
5. 터미널 노드에 대한 목적 코드 생성 루틴이 복귀되면 그 부분의 트리 대신 Acc로 노드를 바꾼다.
6. 구문 트리에서 루트에 대해 목적 코드 생성 루틴을 호출하면 목적 코드를 생성하고 알고리즘을 끝내며,
루트에 대한 목적 코드 생성 루틴이 아니면 2번으로 돌아가서 계속 반복한다.
Target Code Generation Routine
목적 코드 생성 루틴은 재귀적 프로시저로 표현 가능
● 부분 트리 T는 연산자 op와 왼쪽 부분 트리 L, 오른쪽 부분 트리 R로 이뤄진다.
● 부분 트리에는 피연산자인 변수와 Acc, 부분 트리가 있다.
● op′는 op를 실행하는 기계어 명령 코드로 op가 +이면 ADD가 된다.
● T ← Acc는 T를 연산 레지스터 표시로 치환하라는 의미이고, R ← Wi는 부분 트리 R을 Wi로 치환하라는 의미이다.
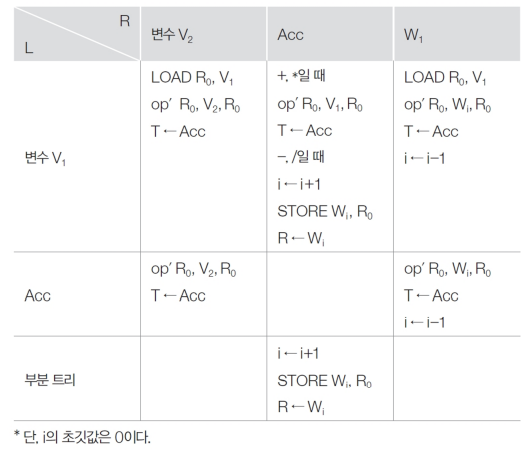
Example
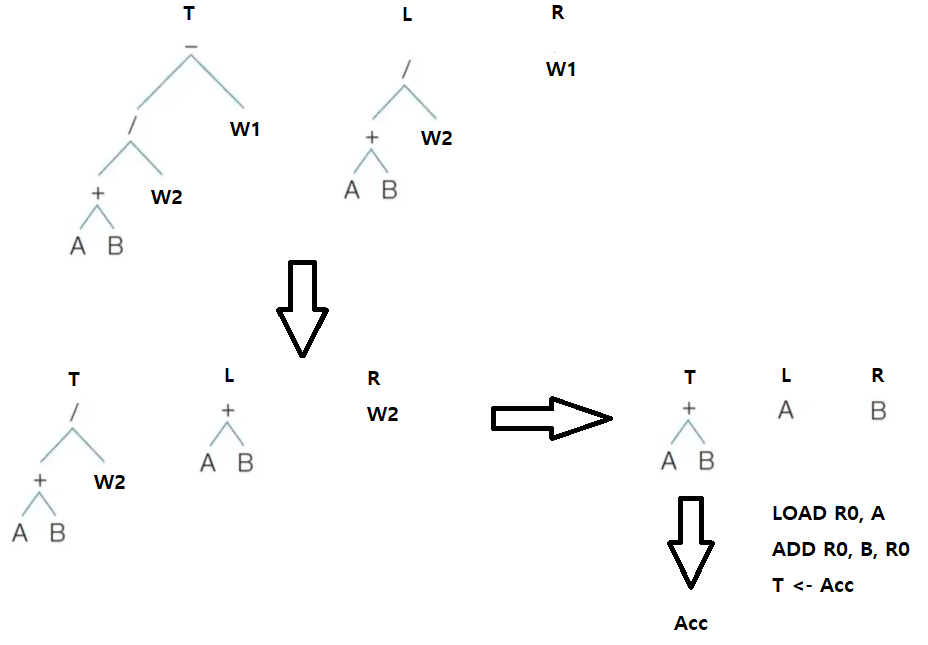
산술식 (A + B) / (C - D) - E * F에 대한 구문 트리가 다음과 같을 때 목적 코드를 구해보자.
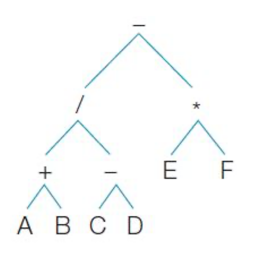
1. LOAD R0, E
MULT R0, F, R0
T <- Acc
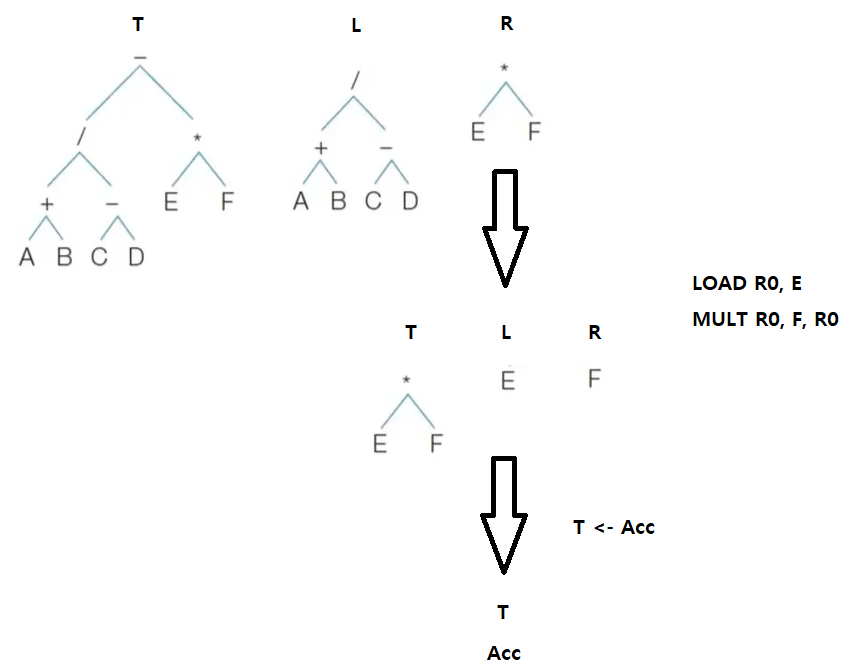
2. i <- i + 1 (i = 1 변경)
STORE W1, R0
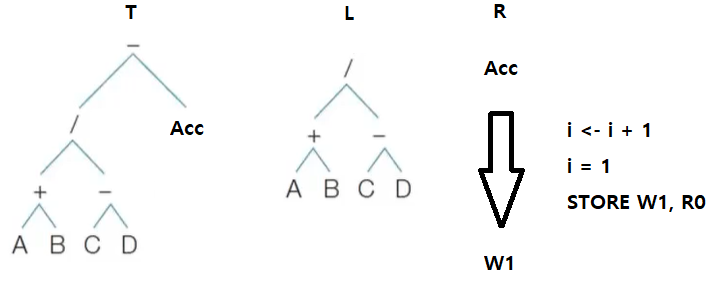
3. LOAD R0, C
SUBT R0, D, R0
T <- Acc
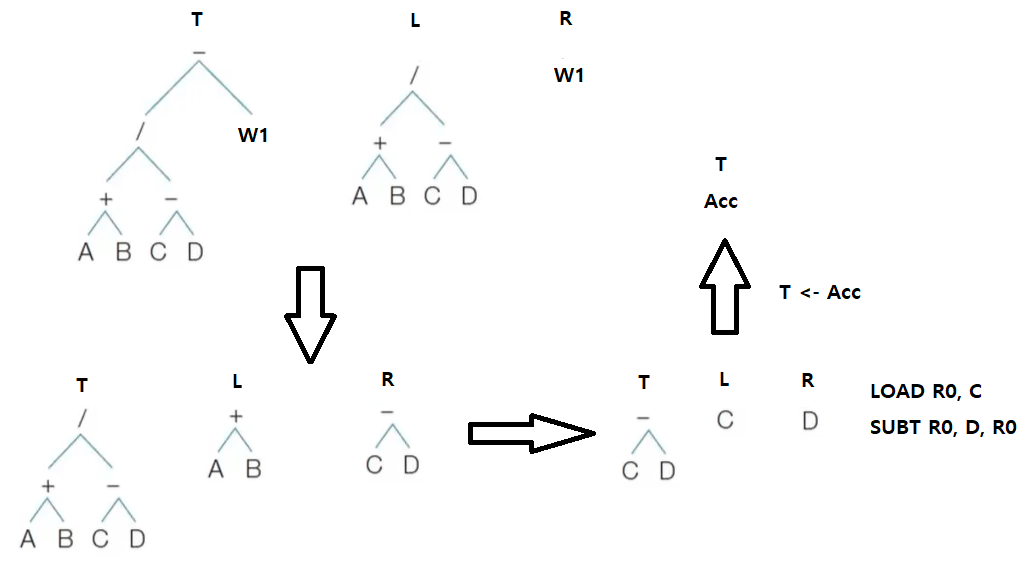
4. i <- i + 1 (i = 2)
STORE W2, R0

5. LOAD R0, A
ADD R0, B, R0
T <- Acc
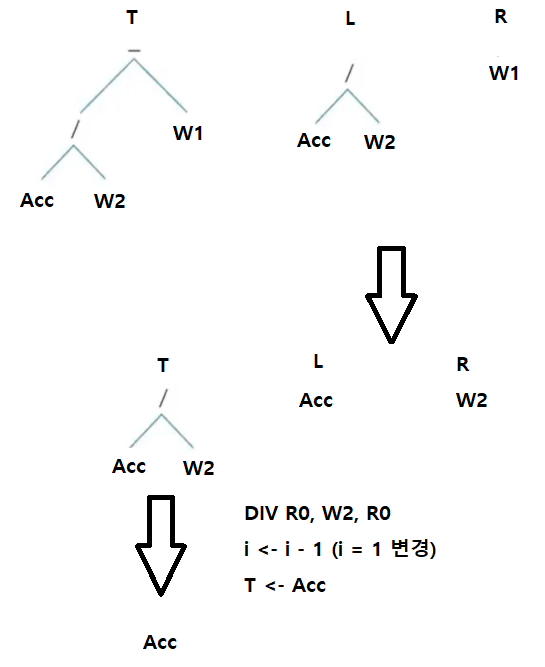
6. DIV R0, W2, R0
i <- i -1 (i = 1 변경)
T <- Acc
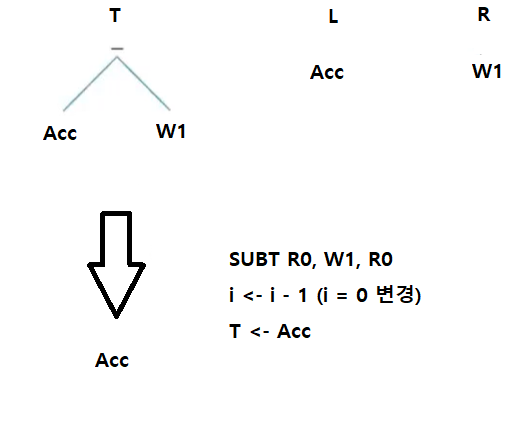
7. SUBT R0, W1, R0
i <- i - 1 (i = 0 변경)
T <- Acc
따라서 목적 코드는 다음과 같다.
1: LOAD R0, E
2: MULT R0, F, R0
3: STORE W1, R0 <= E * F 에 대한 결과 저장!
4: LOAD R0, C
5: SUBT R0, D, R0
6: STORE W2, R0 <= C - D 에 대한 결과 저장!
7: LOAD R0, A
8: ADD R0, B, R0 <= R0에 A + B 에 대한 결과 저장!
9: DIV R0, W2, R0 <= R0에 (A + B) / (C - D) 에 대한 결과 저장!
10: SUBT R0, W1, R0 <= R0에 최종적인 (A + B) / (C - D) - E * F 에 대한 결과 저장!
R0 레지스터에 최종적인 결과 (A + B) / (C - D) - E * F 에 대한 결과가 저장되어 있다.
'학교에서 들은거 정리 > 기초컴파일러구성' 카테고리의 다른 글
| Target code generation - (2) (0) | 2021.12.08 |
|---|---|
| Optimization (0) | 2021.12.01 |
| Parameter Passing, Optimization (0) | 2021.11.29 |
| Structural data type, Runtime Environment (0) | 2021.11.26 |
| Intermediate Code Generation (0) | 2021.11.25 |



